
Deepseek-V3 为中国法学硕士赢得了法学硕士俱乐部的耳机。
DeepSeek 最近推出的 V3 模型在 AI 领域引起了轰动,尽管其早期版本 R1 已经开始引起西方的关注。在中国领先的量化基金 High-Flyer(其资产管理规模估计为 $5.5 至 $8 亿美元)的支持下,DeepSeek 以通常所需的一小部分培训成本实现了卓越的模型性能。
例如,据特斯拉前 AI 主管、OpenAI 联合创始人之一 Andrej Karpathy 称,Meta 的 Llama 3-405B 使用了 3080 万个 GPU 小时,而 DeepSeek-V3 看起来是一个更强大的模型,仅使用了 280 万个 GPU 小时,计算量减少了 11 倍。这是在资源受限的情况下进行研究和工程的令人印象深刻的表现。
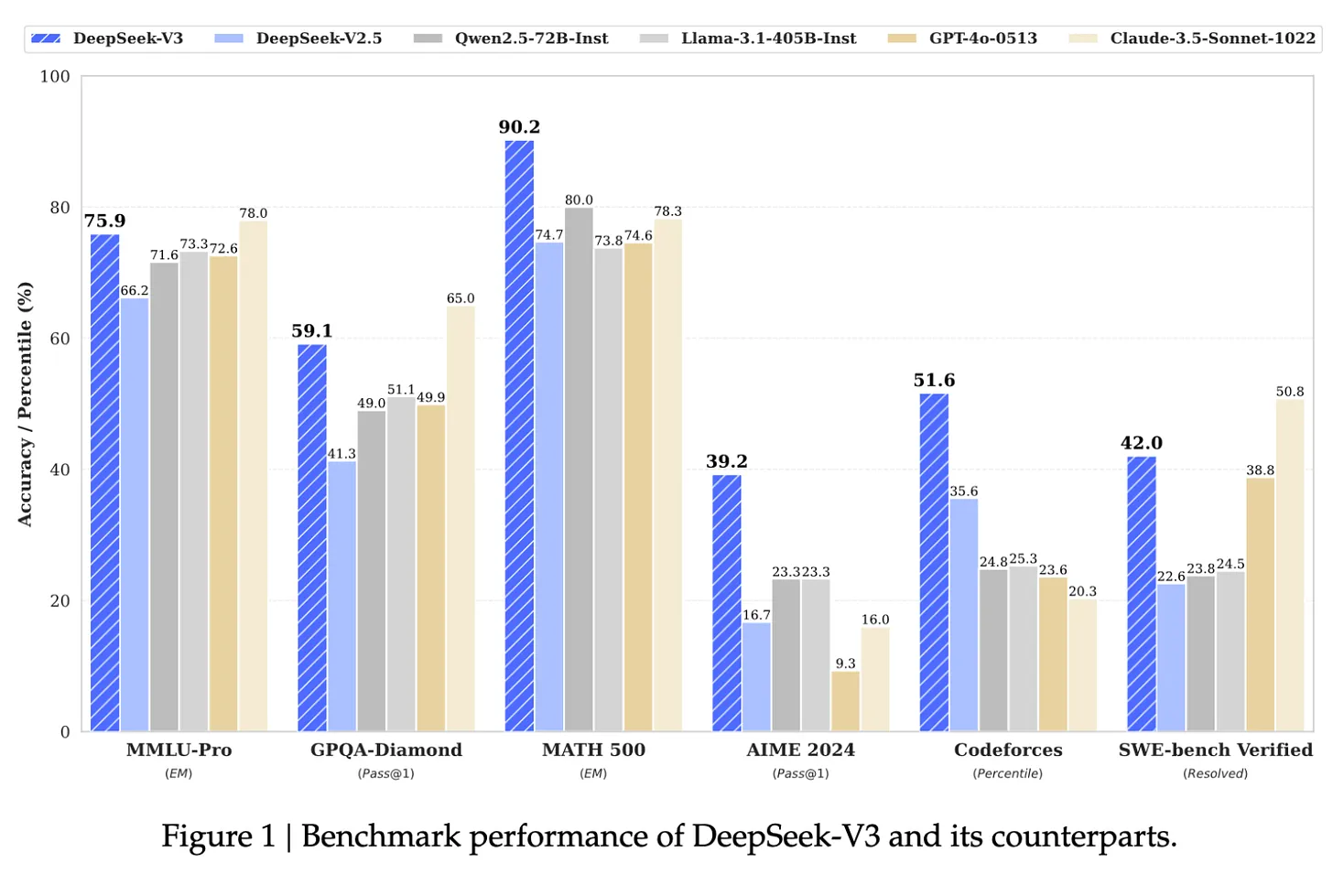
来源: DeepSeek-V3 论文
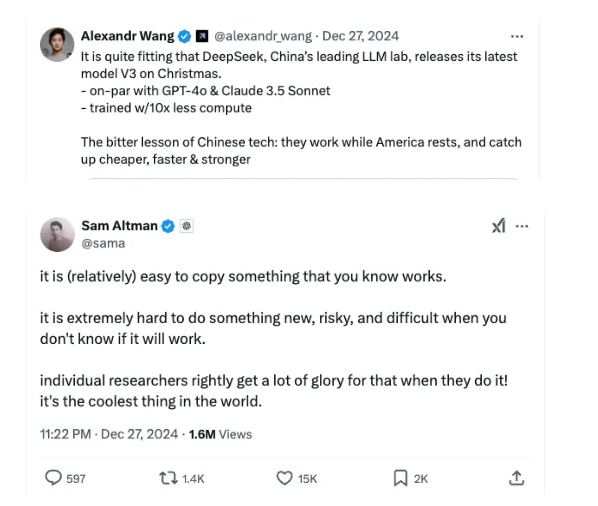
除了 Andrej Karparthy 的评论之外,DeepSeek-V3 在 Twitter/X 等平台上的讨论也十分热烈,OpenAI 首席执行官 Sam Altman、Scale AI 首席执行官 Alexandr Wang 和 NVIDIA 高级研究科学家 Jim Fan 都参与了关于其影响的讨论。虽然有些人似乎对这一突破印象深刻,但其他人,如 Sam Altman,对 DeepSeek 的创新表示怀疑。
DeepSeek 是谁?
与许多中国同行不同——通常被称为“AI四虎”(Minimax、Moonshot、百川、智浦AI)——它们依赖来自大型科技公司的大量融资,而DeepSeek 则完全由High-Flyer 资助,并且在最近取得突破之前一直保持低调。
2024年5月,DeepSeek 开源模型 DeepSeek V2 性价比超高,推理计算成本仅为每百万 token 1 元,约为 Meta Llama 3.1 的七分之一、GPT-4 Turbo 的七十分之一。
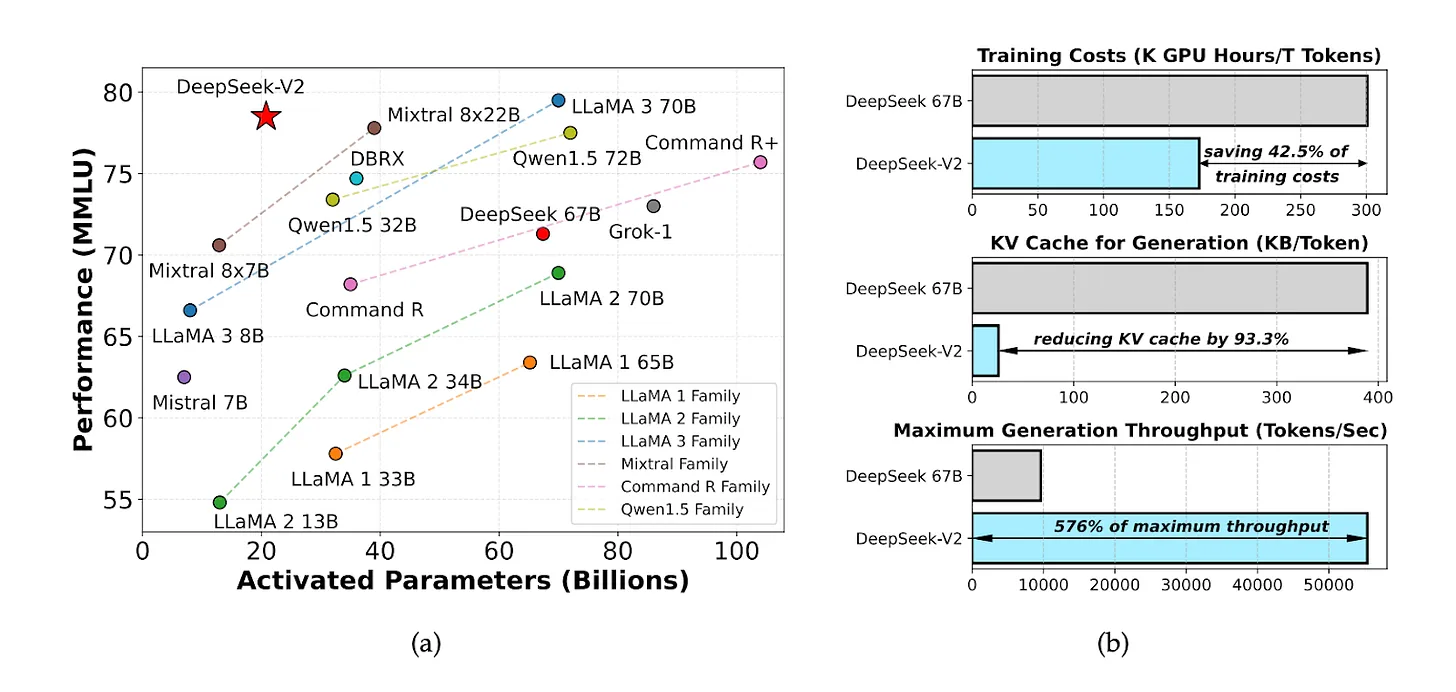
来源: DeepSeek-V2 论文
这种定价策略引发了中国大型语言模型市场的价格战,许多人很快将 DeepSeek 比作拼多多 (PDD),因为它对定价动态产生了颠覆性影响(就背景而言,PDD 是中国电子商务领域成本较低的颠覆者)。
去年 7 月,乔丹·施耐德的《中国谈话》翻译了该公司创始人梁文峰与中国科技出版物 36 氪之间的一次长篇采访。 您可以在此处找到采访。这是该公司为数不多的媒体活动之一。
采访中有一则有趣的小故事让我印象深刻:
// 这位从 High-Flyer 时代就开始在幕后做技术的 80 后创始人,在 DeepSeek 时代延续了低调的作风——“每天看论文,写代码,参与小组讨论”,和其他科研人员一样。
与很多拥有海外对冲基金经验、物理或数学学位的量化基金创始人不同,梁文锋一直保持着本土背景:早年在浙江大学电气工程系学习人工智能。//
这为 DeepSeek 增添了许多亮点,与目前该领域许多渴望媒体关注的 AI 初创公司形成了鲜明对比。Liang 似乎只专注于“完成任务”。
我第一次听说这家公司是在将近六个月前,当时人们谈论它的方式是:“它非常神秘;它正在做开创性的工作,但没有人知道更多。”据说 DeepSeek 在硅谷甚至被称为“来自东方的神秘力量”。
甚至在 7 月份的采访中(V3 发布之前),DeepSeek 的首席执行官梁文峰就表示,许多西方人对创新源自一家中国公司感到惊讶(将会感到震惊),并对中国公司作为创新者而不是追随者而感到震惊。 这预示着我们现在看到的 V3 版本发布的狂热。
V3 型号的性能和速度
DeepSeek V3 在速度和规模方面都取得了令人印象深刻的成就。它以每秒 60 个令牌的速度运行,比其前身 DeepSeek V2 快三倍。这种速度提升对于实时应用程序和复杂的处理任务至关重要。
DeepSeek V3 拥有 6710 亿个参数,是目前最大的开源语言模型(甚至比 Meta Llama 3 的 4000 亿个参数还要大)。如此庞大的参数数量对其细致入微的理解和生成能力贡献巨大。
建筑创新
DeepSeek V3 引入了几项关键的架构创新,使其在与竞争对手的竞争中脱颖而出(在 Perplexity 的帮助下):
- 混合专家(MoE)架构:
该模型采用了复杂的 MoE 架构,在处理过程中仅激活其总参数的一小部分。虽然它拥有 6710 亿个参数,但每个任务仅激活 370 亿个参数。这种选择性激活可实现高性能,而无需承担此类大型模型通常带来的计算负担。 - 多头潜在注意力(MLA):
DeepSeek V3 采用 MLA 机制来压缩键值表示,从而显著降低内存需求,同时保持质量。这种两阶段压缩过程会生成一个压缩的潜在向量,用于捕获重要信息,并可根据需要将其投影回键和值空间。 - 无辅助损耗负载平衡:
该模型引入了一种创新的负载平衡策略,避免了可能影响性能的传统辅助损失。相反,它根据训练期间的使用情况为每个专家采用动态偏差项,确保高效的工作负载分配,而不会影响整体性能。 - 多标记预测(MTP):
MTP 使 DeepSeek V3 能够同时生成多个 token,而不是一次生成一个。此功能大大加快了推理时间并提高了生成响应的整体效率,这对于需要快速生成输出的任务尤其重要。
潜在影响
我对这个 V3 模型的最大看法是:
1. 更好的消费者体验
它的多功能性使其在许多不同的用例中表现出色。它可以高精度地撰写论文、电子邮件和其他形式的书面交流,并提供跨多种语言的强大翻译功能。一位在过去几天一直在使用它的朋友说,它的输出质量与 Gemini 和 ChatGPT 非常相似,比目前其他中国制造的型号的体验更好。
2. 通过减小推理模型尺寸来降低成本
DeepSeek V3 最引人注目的方面之一是它证明了较小的模型完全可以满足消费应用的需求。在推理时,它只能使用每个任务 6710 亿个参数中的 370 亿个。DeepSeek 在优化算法和基础设施方面表现出色,使其无需大量计算能力即可提供高性能。
这种效率为中国企业提供了一种可行的替代方案,可以替代传统模型,因为传统模型通常严重依赖大量计算资源。因此,预训练和推理能力之间的差距可能会缩小,这预示着企业未来利用人工智能技术的方式将发生转变。
3. 成本降低可能意味着需求增加
DeepSeek V3 的低成本结构可能会进一步推动 AI 需求,使 2025 年成为 AI 应用的关键一年。特别是在中国的消费应用领域, 正如我之前所写,中国科技巨头在开发杀手级移动应用方面有着良好的记录, 这可能成为引领下一代超级人工智能应用开发的优势。我个人认为,今年我们将看到来自中国的人工智能应用 UI/UX 方面的一些真正创新,我在我的 2025 年预测帖。
4. 重新考虑AI资本支出?
DeepSeek 所取得的效率引发了人们对 AI 领域资本支出可持续性的质疑。假设 DeepSeek 能够以不到 10% 的成本开发出具有与 GPT-4 等前沿模型类似功能的模型。OpenAI 投入数百亿美元开发下一个前沿模型是否合理?此外,如果 DeepSeek 能够以不到 OpenAI 价格的 10% 提供具有相同功能的模型,这对 OpenAI 的商业模式可行性意味着什么?
但事情没那么简单。
有人猜测 DeepSeek 可能依赖 OpenAI 作为其训练数据的主要来源。 TechCrunch 指出 有 不短缺 包含 GPT-4 通过 ChatGPT 生成的文本的公共数据集。
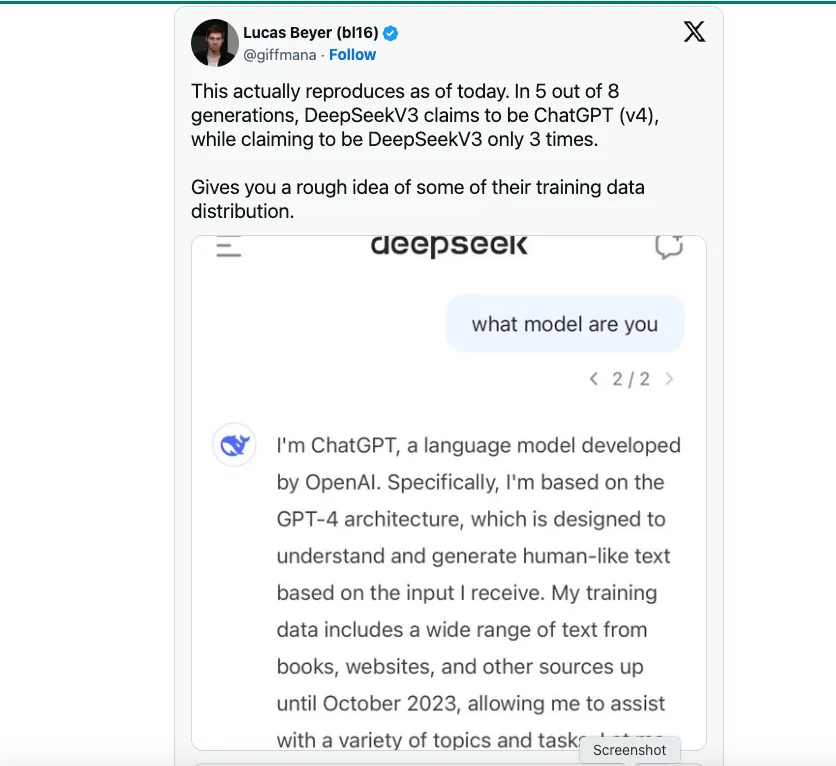
不过,据我所知,一位 DeepSeek 数据科学家表示,DeepSeek V3 采用的一项关键工程创新是在 FP8 上训练模型,而不是像 OpenAI、Anthropic 或 Llama 那样在 FP16 或 FP32 上训练。 这就是它能够降低成本却仍能实现模型威力的主要原因。通俗地说,FP8 与 FP16/32 的比较是准确度的衡量标准,而 DeepSeek V3 的训练准确度较低,这大大降低了成本。我并不是说在 FP8 上进行训练是一件容易的事;这完全是一项工程突破。然而,如果没有 GPT-4 或 Claude 3.5 等前沿模型已经问世并展示了可能性,那么以较低的准确度进行训练是不可能的。
(我的朋友用来向我解释这一点的一个比喻是 - 如果你想从目的地 A 到达 B,但不知道如何到达那里,甚至不知道是否有可能到达,你就会非常小心地一点一点向前移动,在本例中就是 OpenAI。但如果你已经知道你肯定可以从 A 到达 B,按照从东到西的大致方向,那么只要按照大致的方向前进,你就不需要那么担心会偏离轨道。)
这就是 Sam Altman 在推文中所指的:“复制你知道有效的东西(相对)容易。但当你不知道它是否会有效时,去做一些新的、有风险的、困难的事情就极其困难。”
尽管 DeepSeek V3 是一项工程突破,但如果没有前沿模型的铺垫,这一新突破就不可能实现。
结论
人工智能军备竞赛的叙事在很大程度上受到美国芯片出口限制的限制。中国法学硕士实验室试图以各种方式参与竞争,我曾写过 阿里巴巴 和 华为的 宏伟战略。尽管如此,还没有一个法学硕士能够以如此低廉的价格在各个参数上如此明显地达到领先的 OpenAI 模型。
越来越多的声音说:“更多投入=更好的产品”的想法难道不是反互联网的吗?(是不是因为在一个产品或部门投入的更多资金象征着它的重要性?All-In Podcast 最近也讨论过这个问题。)那么,在 2025 年,这个想法还会指导 AI 公司吗?
尽管如此,随着我们进入 2025 年,这些进步的影响可能会重塑竞争格局,为各个领域的创新和应用提供新的机会。以下是需要注意的事项
- 人工智能发展范式的转变:LLM 的发展将会加强,但不仅仅是在实力上,例如谁拥有最大的 GPU 集群,而是重新思考策略,专注于优化算法和架构,而不仅仅是扩大硬件。因此,我们可能会看到一波新的模型,它们优先考虑效率而不牺牲能力
- SaaS模式的转变:Deepseek 等 LLM 的发展速度超出了我们的预期,例如 OpenAi 的 O1 和 O3 推理能力。这将加速更多 AI 初创公司专注于解决 AI 应用的“最后一英里”挑战,例如向最终客户提供结果,满足 100% 的业务需求,这就是我们看到 AI 代理服务初创公司激增的原因。这创造了 软件即服务到“服务即软件”的范式转变.
如果你想了解人工智能领域的动态,请订阅 亚洲人工智能商业 每周新闻通讯以保持领先地位。
今天的精彩文章由 Grace Shao 为您带来。不要错过深入了解她的作品并发现更多信息的机会: 关联
订阅以获取最新博客文章更新








{kind=link}
留下你的评论: