
Deepseek-V3 giúp China LLM giành được chứng chỉ của LLM Club.
Việc DeepSeek ra mắt mô hình V3 gần đây đã tạo nên làn sóng lan tỏa trong bối cảnh AI, ngay cả khi phiên bản trước đó của nó, R1, đã bắt đầu thu hút sự chú ý ở phương Tây. Được hỗ trợ bởi một trong những quỹ định lượng hàng đầu của Trung Quốc, High-Flyer, tự hào có AUM ước tính từ $5,5 đến $8 tỷ, DeepSeek đã đạt được hiệu suất mô hình đáng chú ý với một phần nhỏ chi phí đào tạo thường yêu cầu.
Ví dụ, theo Andrej Karpathy, cựu giám đốc AI của Tesla và là một trong những người đồng sáng lập OpenAI, Llama 3-405B của Meta đã sử dụng 30,8 triệu giờ GPU, trong khi DeepSeek-V3 có vẻ là một mô hình mạnh hơn với chỉ 2,8 triệu giờ GPU, ít tính toán hơn 11 lần. Đây là một màn trình diễn cực kỳ ấn tượng về nghiên cứu và kỹ thuật trong điều kiện hạn chế về nguồn lực.
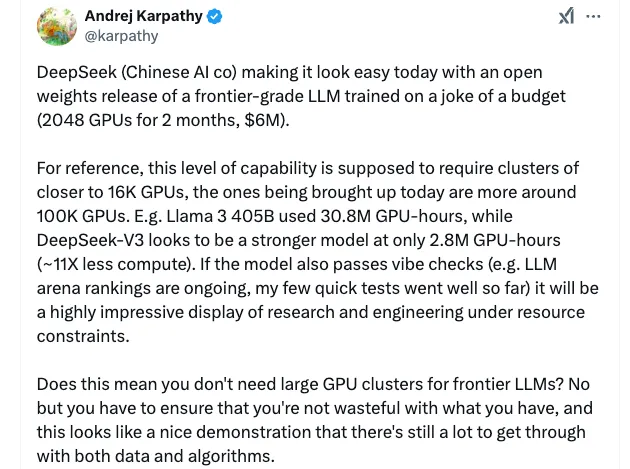
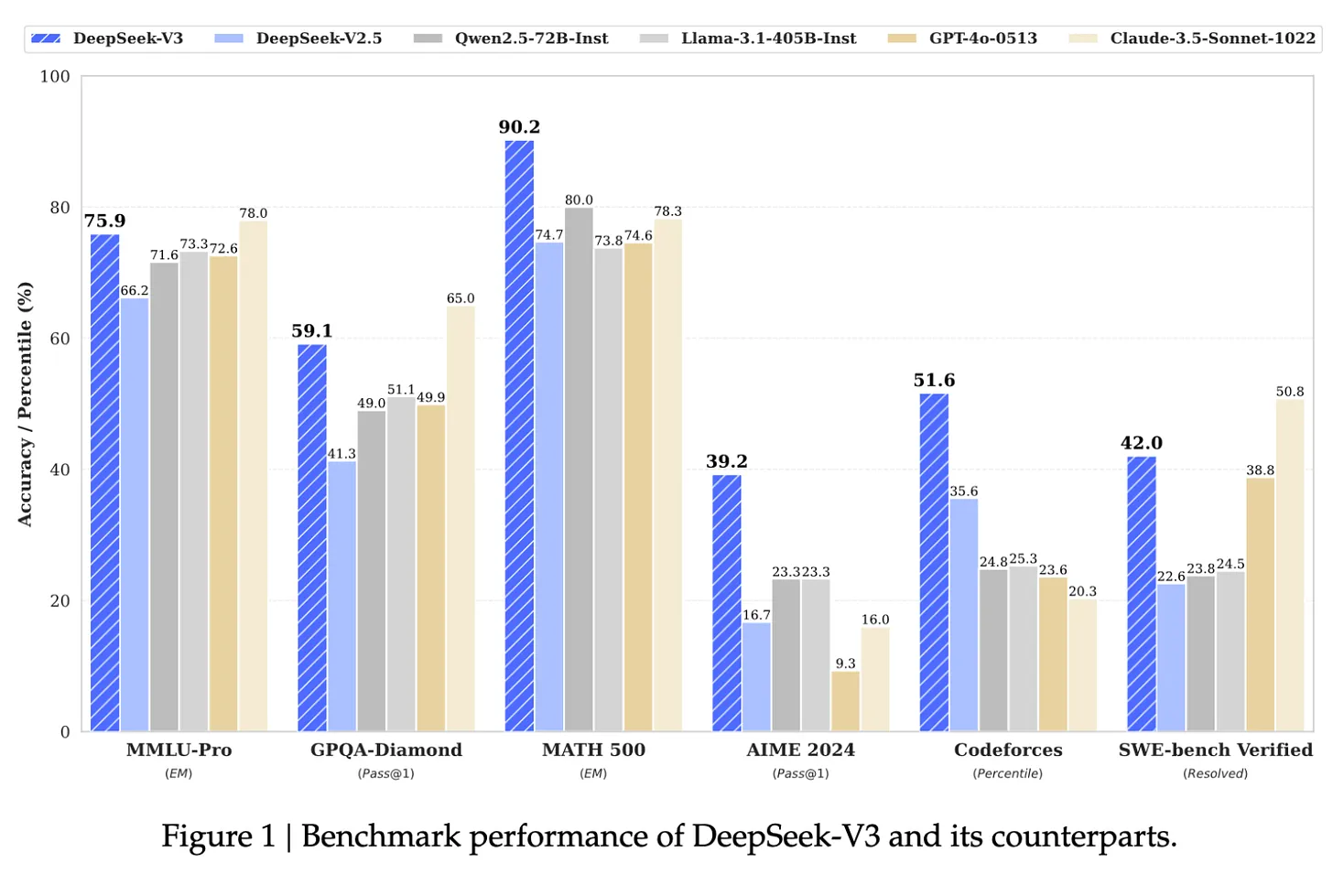
Nguồn: Bài báo DeepSeek-V3
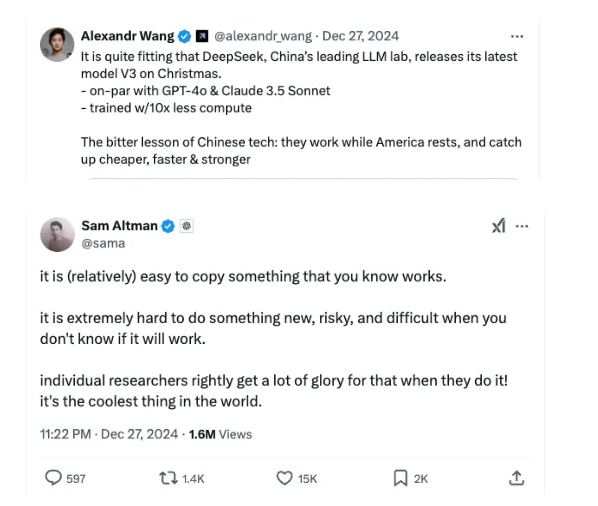
Ngoài những bình luận của Andrej Karparthy, tiếng vang xung quanh DeepSeek-V3 đã được cảm nhận rõ ràng trên các nền tảng như Twitter/X, nơi Sam Altman (CEO của OpenAI), Alexandr Wang (CEO của Scale AI) và Jim Fan (Nhà khoa học nghiên cứu cấp cao tại NVIDIA) đã tham gia thảo luận về ý nghĩa của nó. Trong khi một số người có vẻ ấn tượng với bước đột phá này, những người khác, như Sam Altman, lại tỏ ra hoài nghi về những cải tiến của DeepSeek.
DeepSeek là ai?
Không giống như nhiều đối thủ Trung Quốc khác - thường được gọi là "bốn con hổ AI" (Minimax, Moonshot, Baichuan, Zhipu AI) - vốn dựa vào nguồn vốn gây quỹ đáng kể từ các công ty công nghệ lớn, DeepSeek được High-Flyer tài trợ toàn bộ và giữ bí mật cho đến khi có bước đột phá gần đây.
Vào tháng 5 năm 2024, DeepSeek đã giới thiệu một mô hình mã nguồn mở có tên là DeepSeek V2, tự hào có tỷ lệ hiệu suất chi phí đặc biệt. Chi phí tính toán suy luận chỉ là 1 nhân dân tệ cho một triệu token—khoảng một phần bảy so với Meta Llama 3.1 và một phần bảy mươi so với GPT-4 Turbo.
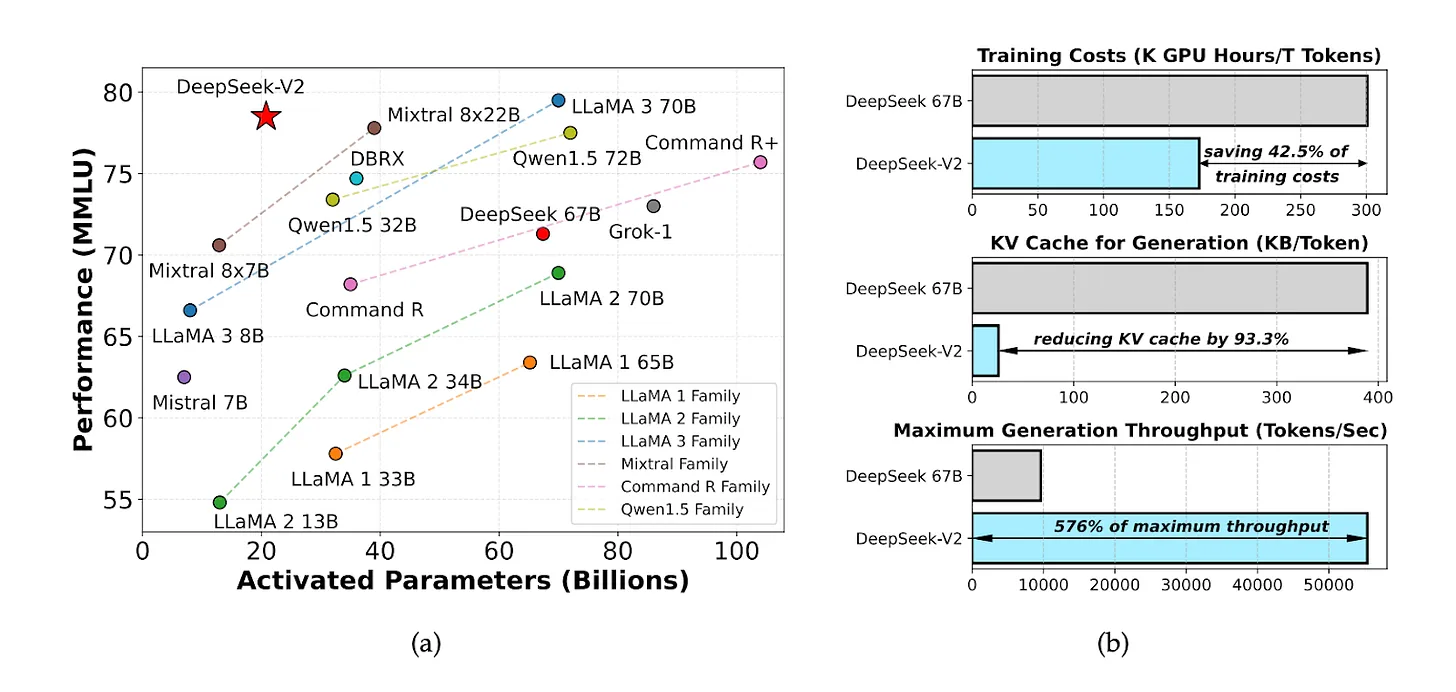
Nguồn: Bài báo DeepSeek-V2
Chiến lược định giá này đã gây ra một cuộc chiến giá cả trên thị trường mô hình ngôn ngữ lớn của Trung Quốc, và nhiều người nhanh chóng ví DeepSeek với Pinduoduo (PDD) vì tác động mang tính đột phá của nó đối với động lực định giá (trong bối cảnh này, PDD là công ty có chi phí thấp hơn trong thương mại điện tử ở Trung Quốc).
Tháng 7 năm ngoái, China Talk của Jordan Schneider đã dịch một cuộc phỏng vấn dài giữa người sáng lập công ty, Liang Wenfeng, và ấn phẩm công nghệ Trung Quốc 36kr. Bạn có thể tìm thấy cuộc phỏng vấn ở đây. Đây là một trong số ít hoạt động truyền thông mà công ty thực hiện.
Một giai thoại nhỏ buồn cười trong cuộc phỏng vấn khiến tôi chú ý:
// Nhà sáng lập sau những năm 80, người đã làm việc đằng sau hậu trường về công nghệ kể từ thời High-Flyer, vẫn tiếp tục phong cách khiêm tốn của mình trong thời đại DeepSeek — “đọc báo cáo, viết mã và tham gia thảo luận nhóm” Đọc báo, nghiên cứu khoa học, tìm hiểu thêm mỗi ngày, giống như mọi nhà nghiên cứu khác.
Không giống như nhiều nhà sáng lập quỹ định lượng — những người có kinh nghiệm làm việc tại quỹ đầu cơ ở nước ngoài và có bằng vật lý hoặc toán học — Liang Wenfeng luôn duy trì xuất thân địa phương: trong những năm đầu, ông đã học về trí tuệ nhân tạo tại Khoa Kỹ thuật Điện của Đại học Chiết Giang.//
Điều này mang lại nhiều màu sắc cho DeepSeek, một sự tương phản rõ rệt với nhiều công ty khởi nghiệp AI đang thèm khát truyền thông trong lĩnh vực này hiện nay. Liang có vẻ chỉ tập trung vào việc "hoàn thành công việc".
Lần đầu tiên tôi nghe nói đến công ty này là gần sáu tháng trước, và mọi người nói về nó như thế này, "Nó rất bí mật; nó đang thực hiện công việc mang tính đột phá, nhưng không ai biết nhiều về nó." DeepSeek thậm chí còn được gọi là "thế lực bí ẩn từ phương Đông" 来自东方的神秘力量 ở Thung lũng Silicon.
Ngay cả trong cuộc phỏng vấn vào tháng 7 (trước khi V3 ra mắt), Giám đốc điều hành của DeepSeek là Liang Wenfeng cho biết nhiều người phương Tây sẽ rất ngạc nhiên khi thấy sự đổi mới bắt nguồn từ một công ty Trung Quốc và kinh ngạc khi thấy các công ty Trung Quốc trở thành những người đổi mới thay vì chỉ là những kẻ đi sau. Thật là điềm báo trước cho sự điên cuồng mà chúng ta đang chứng kiến xung quanh bản phát hành V3 hiện nay.
Hiệu suất và tốc độ của mẫu V3
DeepSeek V3 là một kỳ tích ấn tượng về cả tốc độ và quy mô. Hoạt động ở mức 60 token mỗi giây, nhanh hơn gấp ba lần so với người tiền nhiệm DeepSeek V2. Sự cải tiến tốc độ này rất quan trọng đối với các ứng dụng thời gian thực và các tác vụ xử lý phức tạp.
Với 671 tỷ tham số, DeepSeek V3 là mô hình ngôn ngữ nguồn mở lớn nhất hiện nay (thậm chí còn lớn hơn Meta Llama 3, khoảng 400 tỷ). Số lượng tham số mở rộng này góp phần đáng kể vào khả năng hiểu và tạo ra sắc thái của nó.
Đổi mới kiến trúc
DeepSeek V3 giới thiệu một số cải tiến quan trọng về kiến trúc giúp nó khác biệt so với các đối thủ cạnh tranh (với sự trợ giúp của Perplexity):
- Kiến trúc hỗn hợp chuyên gia (MoE):
Mô hình sử dụng kiến trúc MoE tinh vi, chỉ kích hoạt một phần nhỏ tổng số tham số của nó trong quá trình xử lý. Mặc dù có 671 tỷ tham số, nhưng nó chỉ sử dụng 37 tỷ cho mỗi tác vụ. Kích hoạt có chọn lọc này cho phép hiệu suất cao mà không cần gánh nặng tính toán thường liên quan đến các mô hình lớn như vậy. - Sự chú ý tiềm ẩn đa đầu (MLA):
DeepSeek V3 có cơ chế MLA nén các biểu diễn khóa-giá trị, giảm đáng kể yêu cầu về bộ nhớ trong khi vẫn duy trì chất lượng. Quy trình nén hai giai đoạn này tạo ra một vectơ tiềm ẩn được nén để nắm bắt thông tin cần thiết, có thể được chiếu trở lại các không gian khóa và giá trị khi cần. - Cân bằng tải phụ trợ không mất mát:
Mô hình giới thiệu một chiến lược cân bằng tải sáng tạo giúp tránh các tổn thất phụ trợ truyền thống có thể cản trở hiệu suất. Thay vào đó, nó sử dụng các điều khoản thiên vị động cho mỗi chuyên gia dựa trên việc sử dụng trong quá trình đào tạo, đảm bảo phân phối khối lượng công việc hiệu quả mà không ảnh hưởng đến hiệu suất chung. - Dự đoán đa mã thông báo (MTP):
MTP cho phép DeepSeek V3 tạo ra nhiều mã thông báo cùng lúc thay vì từng mã thông báo một. Khả năng này tăng tốc đáng kể thời gian suy luận và nâng cao hiệu quả tổng thể trong việc tạo phản hồi, điều này đặc biệt quan trọng đối với các tác vụ yêu cầu tạo đầu ra nhanh chóng.
Những hàm ý tiềm ẩn
Những điểm đáng chú ý nhất mà tôi thu thập được từ mẫu V3 này là:
1. Trải nghiệm của người tiêu dùng tốt hơn nhiều
Tính linh hoạt của nó cho phép nó vượt trội trong nhiều trường hợp sử dụng khác nhau. Nó có thể soạn thảo các bài luận, email và các hình thức giao tiếp bằng văn bản khác với độ chính xác cao và cung cấp khả năng dịch mạnh mẽ trên nhiều ngôn ngữ. Một người bạn đã sử dụng nó trong vài ngày qua cho biết rằng đầu ra của nó rất giống với chất lượng của Gemini và ChatGPT, một trải nghiệm tốt hơn so với các mô hình khác do Trung Quốc sản xuất hiện nay.
2. Giảm chi phí thông qua việc giảm kích thước mô hình khi suy luận
Một trong những khía cạnh nổi bật nhất của DeepSeek V3 là minh chứng cho thấy các mô hình nhỏ hơn có thể hoàn toàn đủ cho các ứng dụng của người tiêu dùng. Nó chỉ có thể sử dụng 37 tỷ trong số 671 tỷ tham số cho mỗi tác vụ khi suy luận. DeepSeek đã xuất sắc trong việc tối ưu hóa các thuật toán và cơ sở hạ tầng của mình, cho phép nó cung cấp hiệu suất cao mà không cần sức mạnh tính toán lớn.
Hiệu quả này cung cấp cho các công ty Trung Quốc một giải pháp thay thế khả thi cho các mô hình truyền thống, thường phụ thuộc nhiều vào các nguồn tài nguyên tính toán mở rộng. Do đó, khoảng cách giữa khả năng đào tạo trước và suy luận có thể đang thu hẹp, báo hiệu sự thay đổi trong cách các doanh nghiệp có thể tận dụng công nghệ AI trong tương lai.
3. Chi phí thấp hơn có thể có nghĩa là nhu cầu cao hơn
Cấu trúc chi phí thấp hơn của DeepSeek V3 có khả năng thúc đẩy nhu cầu AI hơn nữa, biến năm 2025 thành năm then chốt cho các ứng dụng AI. Đặc biệt là trong lĩnh vực ứng dụng tiêu dùng của Trung Quốc, như tôi đã viết trước đây, công nghệ lớn của Trung Quốc có thành tích đã được chứng minh trong việc phát triển các ứng dụng di động tuyệt vời, có thể đóng vai trò là lợi thế trong việc dẫn đầu trong việc phát triển ứng dụng AI siêu cấp tiếp theo. Cá nhân tôi nghĩ rằng chúng ta sẽ thấy một số cải tiến thực sự trong UI/UX của ứng dụng AI từ Trung Quốc trong năm nay, điều mà tôi đã viết trong Bài đăng dự đoán năm 2025.
4. Xem xét lại chi phí đầu tư cho AI?
Hiệu quả đạt được của DeepSeek đặt ra câu hỏi về tính bền vững của chi phí vốn trong lĩnh vực AI. Giả sử DeepSeek có thể phát triển các mô hình có khả năng tương tự như các mô hình biên giới như GPT-4 với chi phí thấp hơn 10%. Liệu OpenAI có nên đổ thêm hàng chục tỷ đô la vào việc phát triển mô hình biên giới tiếp theo không? Ngoài ra, nếu DeepSeek có thể cung cấp các mô hình có cùng khả năng với chi phí thấp hơn 10% so với giá của OpenAI, điều này có ý nghĩa gì đối với khả năng tồn tại của mô hình kinh doanh của OpenAI?
Nhưng mọi chuyện không đơn giản như vậy.
Có suy đoán rằng DeepSeek có thể đã dựa vào OpenAI làm nguồn dữ liệu đào tạo chính. TechCrunch chỉ ra rằng có không thiếu của các tập dữ liệu công khai có chứa văn bản được tạo bởi GPT-4 thông qua ChatGPT.
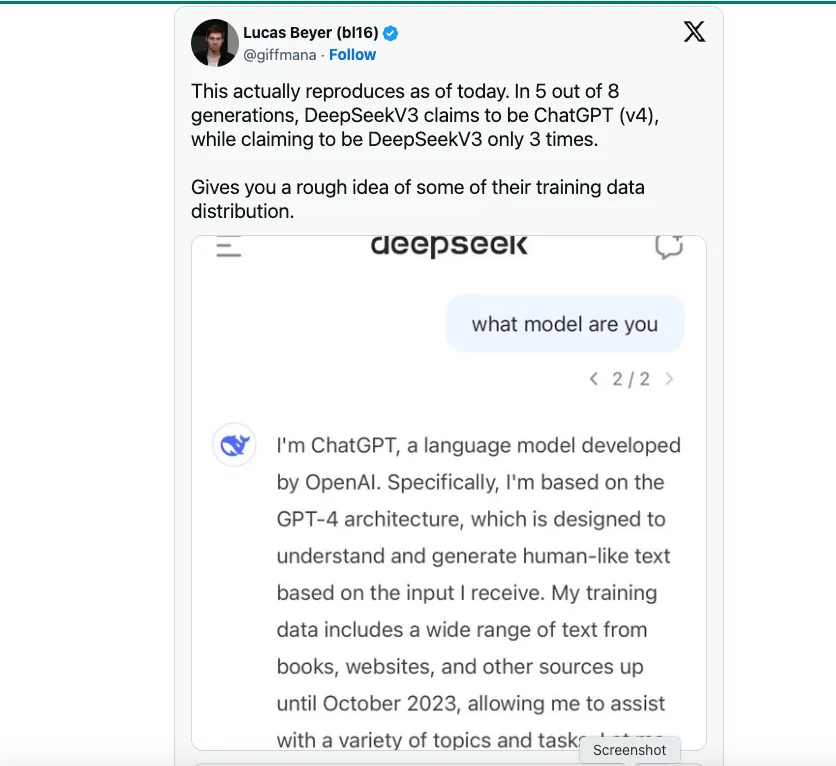
Tuy nhiên, theo những gì tôi nghe được, một nhà khoa học dữ liệu của DeepSeek cho biết một cải tiến kỹ thuật quan trọng mà DeepSeek V3 áp dụng là đào tạo mô hình trên FP8 thay vì FP16 hoặc FP32, như OpenAI, Anthropic hoặc Llama. Đây là lý do chính khiến nó có thể cắt giảm chi phí nhưng vẫn đạt được năng lực của mô hình. Nói một cách dễ hiểu, FP8 so với FP16/32 là phép đo độ chính xác và DeepSeek V3 được đào tạo với độ chính xác thấp hơn, giúp giảm đáng kể chi phí. Tôi không nói rằng đào tạo trên FP8 là một kỳ tích dễ dàng; nó hoàn toàn là một bước đột phá về kỹ thuật. Tuy nhiên, đào tạo với độ chính xác thấp hơn sẽ không thể thực hiện được nếu không có các mô hình biên giới như GPT-4 hoặc Claude 3.5 đã ra mắt và cho thấy những gì có thể.
(Một phép ẩn dụ mà bạn tôi dùng để giải thích điều này với tôi là như thế này - nếu bạn muốn đi từ điểm đến A đến B nhưng không biết làm thế nào để đến đó và thậm chí không biết có thể đến đó hay không, bạn sẽ phải rất cẩn thận tiến từng bước một, tức là OpenAI trong trường hợp này. Nhưng nếu bạn đã biết chắc chắn rằng bạn có thể đi từ A đến B theo hướng chung từ Đông sang Tây, thì bạn sẽ không cần phải cảnh giác với việc đi chệch hướng nếu bạn chỉ cần đi theo hướng chung chung.)
Đây chính là điều Sam Altman đã nhắc đến trong dòng tweet của mình: “Việc sao chép thứ mà bạn biết là hiệu quả thì (tương đối) dễ dàng. Nhưng việc làm điều gì đó mới mẻ, mạo hiểm và khó khăn khi bạn không biết liệu nó có hiệu quả hay không thì lại cực kỳ khó khăn”.
Mặc dù DeepSeek V3 là một bước đột phá về mặt kỹ thuật, nhưng nếu không có các mô hình tiên tiến mở đường, bước đột phá mới này sẽ không thể thực hiện được.
Phần kết luận
Câu chuyện về cuộc chạy đua vũ trang AI phần lớn đã bị giới hạn ở các hạn chế xuất khẩu chip của Hoa Kỳ. Nhiều phòng thí nghiệm LLM của Trung Quốc đã cố gắng cạnh tranh theo nhiều cách khác nhau và tôi đã viết về Alibaba Và Huawei của chiến lược lớn. Tuy nhiên, chưa có LLM nào thực sự có thể tiếp cận mô hình OpenAI hàng đầu một cách rõ ràng như vậy trên nhiều thông số với mức giá chỉ bằng một phần nhỏ.
Ngày càng có nhiều tiếng nói cho rằng, "Ý tưởng chi tiêu nhiều hơn không phải = sản phẩm tốt hơn là chống lại internet sao?" (Có phải vì đầu tư nhiều tiền hơn vào một sản phẩm hoặc bộ phận tượng trưng cho tầm quan trọng của nó không? Podcast All-In gần đây cũng đã thảo luận về điều này.) Vậy, liệu ý tưởng này có còn định hướng cho các công ty AI vào năm 2025 không?
Tuy nhiên, khi chúng ta tiến về phía trước vào năm 2025, những tác động của những tiến bộ này có thể sẽ định hình lại bối cảnh cạnh tranh, mang đến những cơ hội mới cho sự đổi mới và ứng dụng trong nhiều lĩnh vực khác nhau. Và đây là những điều cần chú ý
- Sự thay đổi trong mô hình phát triển AI: Sự phát triển của LLM sẽ tăng cường nhưng không chỉ trên cơ bắp, ví dụ ai sở hữu cụm GPU lớn nhất thay vì suy nghĩ lại về các chiến lược, tập trung vào việc tối ưu hóa các thuật toán và kiến trúc thay vì chỉ mở rộng phần cứng. Kết quả là, chúng ta có thể chứng kiến một làn sóng các mô hình mới ưu tiên hiệu quả mà không hy sinh khả năng
- Sự chuyển đổi của mô hình SaaS: LLM như Deepseek đang tiến triển nhanh hơn chúng ta dự đoán, ví dụ khả năng lý luận của O1 và O3 từ OpenAi. Điều này sẽ thúc đẩy nhiều công ty khởi nghiệp AI hơn tập trung vào việc giải quyết Thách thức “dặm cuối” của các ứng dụng AI, ví dụ như cung cấp kết quả cho khách hàng cuối, đáp ứng 100% yêu cầu kinh doanh, đó là lý do tại sao chúng ta thấy sự gia tăng của các công ty khởi nghiệp dịch vụ đại lý AI. Điều đó tạo ra Chuyển đổi mô hình từ phần mềm dưới dạng dịch vụ sang “dịch vụ dưới dạng phần mềm”.
Nếu bạn muốn theo dõi những thay đổi đang diễn ra trong thế giới AI, hãy đăng ký AI Kinh doanh Châu Á bản tin hàng tuần để luôn đi đầu.
Bài viết sâu sắc hôm nay được mang đến cho bạn bởi Grace Shao. Đừng bỏ lỡ cơ hội tìm hiểu sâu hơn về công việc của cô ấy và khám phá thêm: Liên kết
Đăng ký để nhận thông tin cập nhật bài viết mới nhất trên blog
Bạn cũng có thể thích








{kind=link}
Để lại bình luận của bạn: