
Deepseek-V3 ทำให้ China LLM ได้รับชุดหูฟัง LLM Club
การเปิดตัวโมเดล V3 ล่าสุดของ DeepSeek ทำให้เกิดกระแสตอบรับที่ดีต่อวงการ AI แม้ว่าโมเดล R1 รุ่นก่อนหน้าจะเริ่มได้รับความสนใจจากทั่วโลกแล้วก็ตาม ด้วยการสนับสนุนจากกองทุนเชิงปริมาณชั้นนำของจีนอย่าง High-Flyer ซึ่งมีสินทรัพย์ภายใต้การจัดการประมาณ $5.5 ถึง $8 พันล้าน DeepSeek จึงสามารถสร้างประสิทธิภาพของโมเดลได้อย่างโดดเด่นด้วยต้นทุนการฝึกอบรมที่น้อยกว่าต้นทุนปกติเพียงเล็กน้อย
ตัวอย่างเช่น ตามที่ Andrej Karpathy อดีตหัวหน้าฝ่าย AI ของ Tesla และหนึ่งในผู้ร่วมก่อตั้ง OpenAI กล่าวไว้ Llama 3-405B ของ Meta ใช้ GPU 30.8 ล้านชั่วโมง ขณะที่ DeepSeek-V3 ดูเหมือนจะเป็นโมเดลที่แข็งแกร่งกว่าโดยใช้ GPU เพียง 2.8 ล้านชั่วโมง ซึ่งประมวลผลได้น้อยกว่า 11 เท่า นี่คือการแสดงผลงานวิจัยและวิศวกรรมที่น่าประทับใจอย่างยิ่งภายใต้ข้อจำกัดด้านทรัพยากร
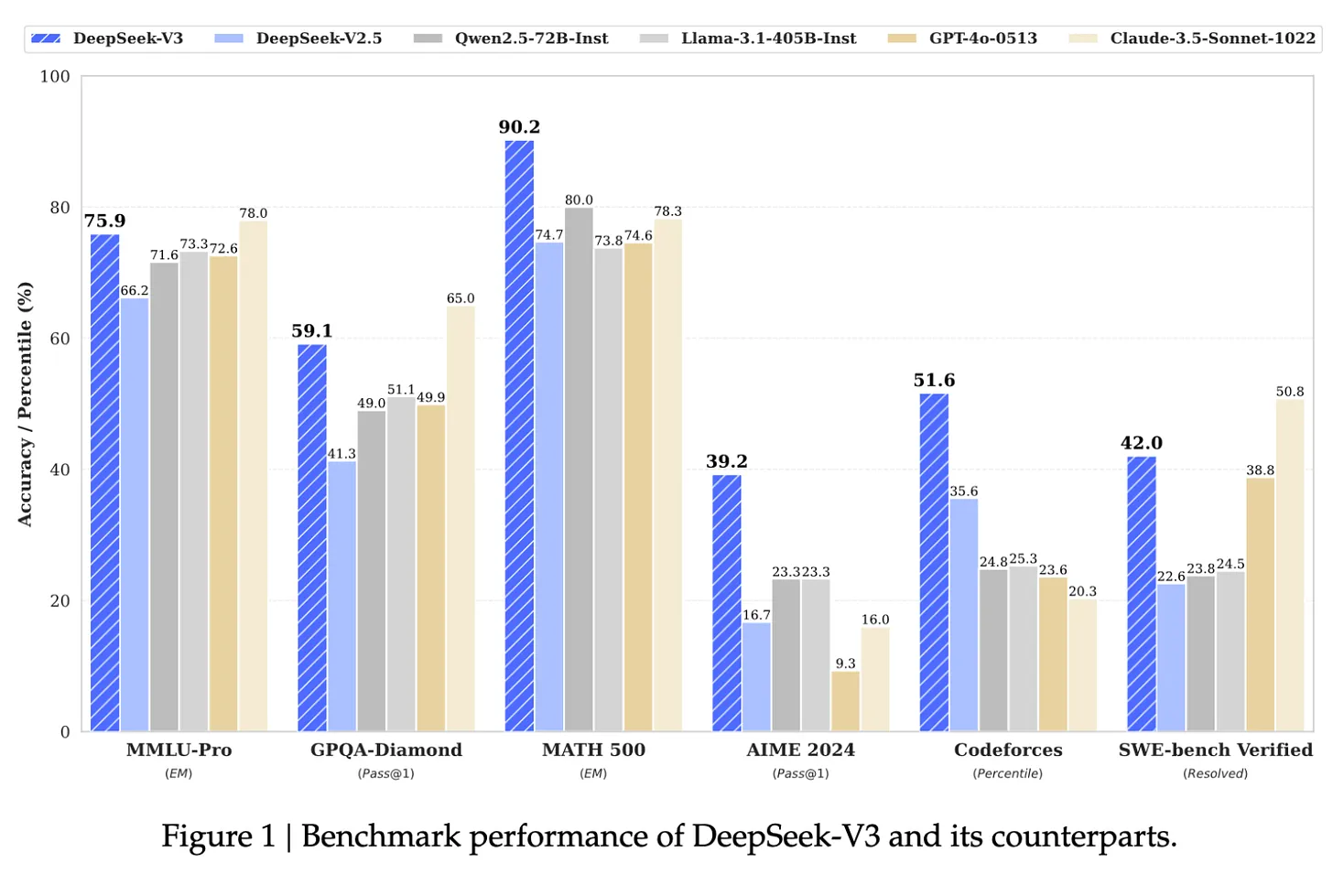
แหล่งที่มา: เอกสาร DeepSeek-V3
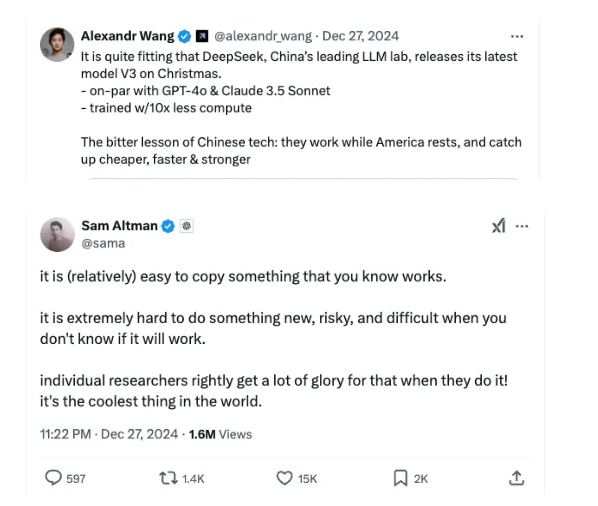
นอกเหนือจากความคิดเห็นของ Andrej Karparthy แล้ว กระแสตอบรับของ DeepSeek-V3 ยังชัดเจนบนแพลตฟอร์มอย่าง Twitter/X ซึ่ง Sam Altman (CEO ของ OpenAI), Alexandr Wang (CEO ของ Scale AI) และ Jim Fan (นักวิจัยอาวุโสของ NVIDIA) ได้ร่วมหารือเกี่ยวกับผลกระทบของ DeepSeek ในขณะที่บางคนดูเหมือนจะประทับใจกับความก้าวหน้าครั้งสำคัญนี้ ในขณะที่บางคน เช่น Sam Altman กลับแสดงความไม่เชื่อมั่นต่อนวัตกรรมของ DeepSeek
DeepSeek คือใคร?
ต่างจากคู่แข่งชาวจีนหลายๆ รายที่มักเรียกกันว่า “สี่เสือแห่ง AI” (Minimax, Moonshot, Baichuan, Zhipu AI) ซึ่งต้องพึ่งพาการระดมทุนจำนวนมากจากบริษัทเทคโนโลยียักษ์ใหญ่ DeepSeek นั้นได้รับเงินทุนทั้งหมดจาก High-Flyer และมีโปรไฟล์ต่ำจนกระทั่งประสบความสำเร็จเมื่อไม่นานนี้
ในเดือนพฤษภาคม 2024 DeepSeek ได้เปิดตัวโมเดลโอเพ่นซอร์สที่มีชื่อว่า DeepSeek V2 ซึ่งมีอัตราส่วนต้นทุนต่อประสิทธิภาพที่ยอดเยี่ยม ต้นทุนการประมวลผลอนุมานอยู่ที่เพียง 1 หยวนต่อหนึ่งล้านโทเค็น ซึ่งประมาณหนึ่งในเจ็ดของ Meta Llama 3.1 และหนึ่งในเจ็ดสิบของ GPT-4 Turbo
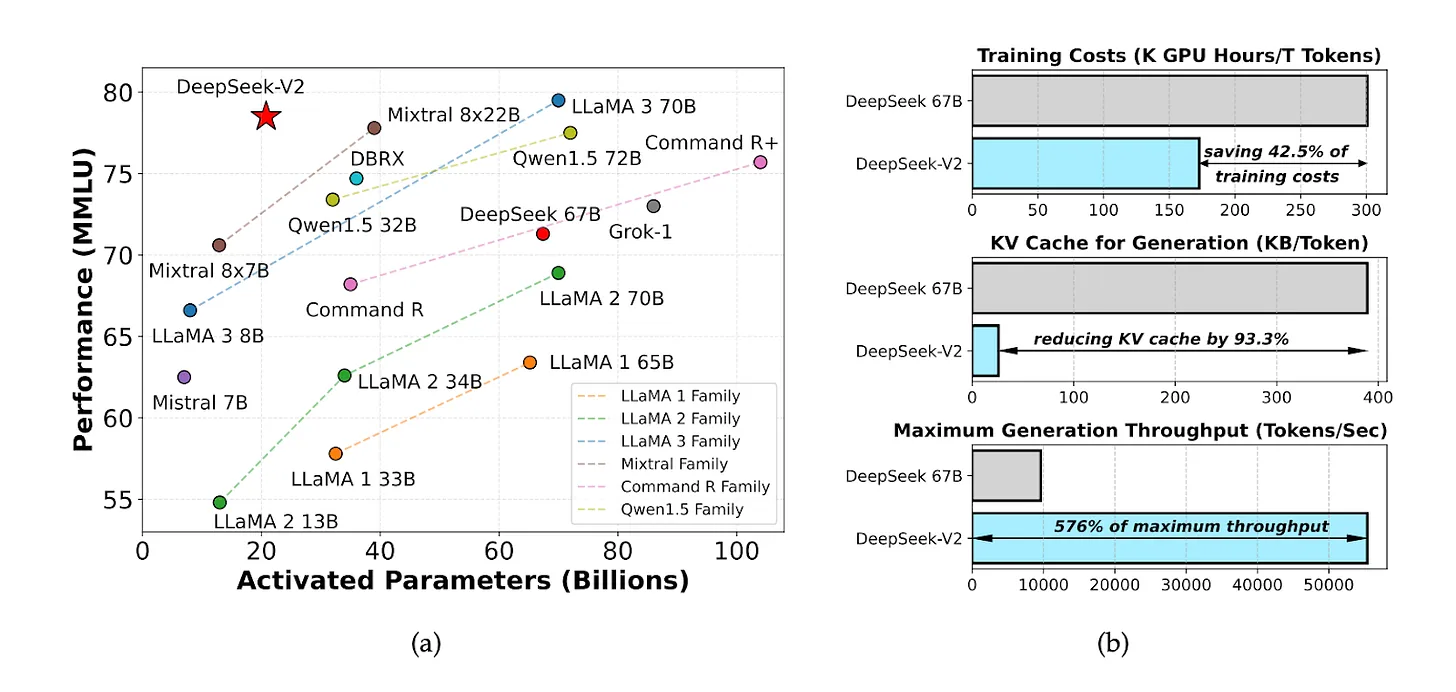
แหล่งที่มา: เอกสาร DeepSeek-V2
กลยุทธ์การกำหนดราคานี้กระตุ้นให้เกิดสงครามราคาในตลาดที่มีโมเดลภาษาขนาดใหญ่ของจีน และหลายๆ คนก็เปรียบเทียบ DeepSeek กับ Pinduoduo (PDD) อย่างรวดเร็ว เนื่องจากมีผลกระทบต่อการเปลี่ยนแปลงราคาอย่างมาก (เพื่อให้เข้าใจในบริบทนี้ PDD คือตัวเปลี่ยนแปลงต้นทุนที่ต่ำกว่าในอีคอมเมิร์ซในประเทศจีน)
เดือนกรกฎาคมที่ผ่านมา รายการ China Talk ของ Jordan Schneider แปลบทสัมภาษณ์ยาวระหว่างผู้ก่อตั้งบริษัท นาย Liang Wenfeng และสำนักพิมพ์เทคโนโลยีของจีน 36kr สามารถอ่านบทสัมภาษณ์ได้ที่นี่เป็นงานประชาสัมพันธ์เพียงไม่กี่งานที่บริษัทจัดขึ้น
เกร็ดเล็กเกร็ดน้อยตลกๆ จากการสัมภาษณ์ที่โดนใจฉัน:
ผู้ก่อตั้งยุคหลังปี 1980 ซึ่งทำงานเบื้องหลังด้านเทคโนโลยีมาตั้งแต่ยุค High-Flyer ยังคงดำเนินสไตล์เรียบง่ายในยุค DeepSeek — “อ่านเอกสาร เขียนโค้ด และเข้าร่วมการอภิปรายกลุ่ม” ทุกวัน เช่นเดียวกับนักวิจัยคนอื่นๆ
ไม่เหมือนผู้ก่อตั้งกองทุนเชิงปริมาณหลายๆ คนที่มีประสบการณ์ด้านกองทุนป้องกันความเสี่ยงในต่างประเทศและมีปริญญาด้านฟิสิกส์หรือคณิตศาสตร์ Liang Wenfeng ยังคงรักษาภูมิหลังในท้องถิ่นไว้เสมอ โดยในช่วงปีแรกๆ เขาได้ศึกษาด้านปัญญาประดิษฐ์ที่ภาควิชาวิศวกรรมไฟฟ้า มหาวิทยาลัยเจ้อเจียง
สิ่งนี้ทำให้ DeepSeek มีสีสันมากขึ้น ซึ่งแตกต่างอย่างสิ้นเชิงจากสตาร์ทอัพด้าน AI ที่ต้องการสื่อมากกว่าหลายๆ แห่งในอุตสาหกรรมนี้ Liang ดูเหมือนจะมุ่งเน้นแค่ "การทำให้สำเร็จ" เท่านั้น
ฉันได้ยินเกี่ยวกับบริษัทนี้เป็นครั้งแรกเมื่อเกือบหกเดือนที่แล้ว และผู้คนมักพูดถึงบริษัทนี้ว่า "บริษัทนี้เป็นความลับสุดยอด บริษัทกำลังดำเนินการที่ก้าวล้ำ แต่ไม่มีใครรู้จักบริษัทนี้ดีไปกว่านี้อีกแล้ว" DeepSeek ยังถูกเรียกว่า "พลังลึกลับจากตะวันออก" ในซิลิคอนวัลเลย์อีกด้วย
แม้กระทั่งในระหว่างการสัมภาษณ์เดือนกรกฎาคม (ก่อนเปิดตัว V3) Liang Wenfeng ซีอีโอของ DeepSeek กล่าวว่าชาวตะวันตกจำนวนมากรู้สึก (จะรู้สึก) ประหลาดใจที่ได้เห็นนวัตกรรมที่เกิดจากบริษัทจีน และตกใจเมื่อเห็นว่าบริษัทจีนก้าวขึ้นมาเป็นผู้สร้างสรรค์นวัตกรรม แทนที่จะเป็นเพียงผู้ตามเท่านั้น นี่เป็นการบอกเป็นนัยถึงความคลั่งไคล้ที่เรากำลังเห็นรอบๆ การเปิดตัว V3 ในตอนนี้
ประสิทธิภาพและความเร็วของรุ่น V3
DeepSeek V3 ถือเป็นความสำเร็จที่น่าประทับใจทั้งในด้านความเร็วและขนาด โดยทำงานที่ 60 โทเค็นต่อวินาที ซึ่งเร็วกว่ารุ่นก่อนหน้าอย่าง DeepSeek V2 ถึง 3 เท่า การปรับปรุงความเร็วนี้มีความสำคัญอย่างยิ่งสำหรับแอปพลิเคชันแบบเรียลไทม์และงานประมวลผลที่ซับซ้อน
ด้วยพารามิเตอร์ 671 พันล้านตัว DeepSeek V3 ถือเป็นโมเดลภาษาโอเพ่นซอร์สที่ใหญ่ที่สุดในปัจจุบัน (ใหญ่กว่า Meta Llama 3 ซึ่งอยู่ที่ประมาณ 400 พันล้านตัว) จำนวนพารามิเตอร์ที่มากมายนี้ช่วยให้เข้าใจและสร้างข้อมูลได้อย่างละเอียดอ่อนมากขึ้น
นวัตกรรมทางสถาปัตยกรรม
DeepSeek V3 แนะนำนวัตกรรมทางสถาปัตยกรรมที่สำคัญหลายประการที่ทำให้แตกต่างจากคู่แข่ง (ด้วยความช่วยเหลือจาก Perplexity):
- สถาปัตยกรรมแบบผสมผสานผู้เชี่ยวชาญ (MoE):
โมเดลนี้ใช้สถาปัตยกรรม MoE ที่ซับซ้อนซึ่งเปิดใช้งานเพียงเศษเสี้ยวของพารามิเตอร์ทั้งหมดในระหว่างการประมวลผล แม้ว่าจะมีพารามิเตอร์ 671 พันล้านตัว แต่ใช้งานเพียง 37 พันล้านตัวสำหรับแต่ละงาน การเปิดใช้งานแบบเลือกสรรนี้ช่วยให้มีประสิทธิภาพสูงโดยไม่ต้องมีภาระในการคำนวณที่มักเกิดขึ้นกับโมเดลขนาดใหญ่ดังกล่าว - ความสนใจแฝงหลายหัว (MLA):
DeepSeek V3 มีกลไก MLA ที่บีบอัดการแสดงค่าคีย์-ค่า ช่วยลดความต้องการหน่วยความจำได้อย่างมากในขณะที่ยังคงคุณภาพเอาไว้ กระบวนการบีบอัดสองขั้นตอนนี้จะสร้างเวกเตอร์แฝงที่บีบอัดแล้วซึ่งจะรวบรวมข้อมูลสำคัญ ซึ่งสามารถฉายกลับไปยังพื้นที่คีย์และค่าได้ตามต้องการ - การปรับสมดุลโหลดแบบไม่มีการสูญเสียเสริม:
แบบจำลองนี้แนะนำกลยุทธ์การปรับสมดุลโหลดที่สร้างสรรค์ซึ่งหลีกเลี่ยงการสูญเสียเสริมแบบเดิมที่อาจขัดขวางประสิทธิภาพการทำงาน แทนที่จะเป็นเช่นนั้น แบบจำลองนี้จะใช้เงื่อนไขอคติแบบไดนามิกสำหรับผู้เชี่ยวชาญแต่ละคนตามการใช้งานระหว่างการฝึกอบรม เพื่อให้แน่ใจว่ามีการกระจายภาระงานอย่างมีประสิทธิภาพโดยไม่กระทบต่อประสิทธิภาพโดยรวม - การทำนายหลายโทเค็น (MTP):
MTP ช่วยให้ DeepSeek V3 สร้างโทเค็นได้หลายรายการพร้อมกันแทนที่จะสร้างทีละรายการ ความสามารถนี้ทำให้เวลาในการอนุมานเร็วขึ้นอย่างมากและเพิ่มประสิทธิภาพโดยรวมในการสร้างการตอบสนอง ซึ่งเป็นสิ่งสำคัญอย่างยิ่งสำหรับงานที่ต้องใช้การสร้างเอาต์พุตอย่างรวดเร็ว
ผลกระทบที่อาจเกิดขึ้น
สิ่งสำคัญที่สุดที่ฉันรวบรวมได้เกี่ยวกับโมเดล V3 นี้คือ:
1. ประสบการณ์ผู้บริโภคที่ดีขึ้นมาก
ความคล่องตัวทำให้โปรแกรมนี้สามารถทำงานได้ดีในหลายกรณี สามารถเขียนเรียงความ อีเมล และรูปแบบการสื่อสารด้วยลายลักษณ์อักษรอื่นๆ ได้อย่างแม่นยำ และยังมีความสามารถในการแปลที่ยอดเยี่ยมในหลายภาษา เพื่อนคนหนึ่งซึ่งใช้งานโปรแกรมนี้มาสองสามวันแล้วบอกว่าผลลัพธ์ที่ได้นั้นมีคุณภาพใกล้เคียงกับ Gemini และ ChatGPT มาก ซึ่งให้ประสบการณ์ที่ดีกว่ารุ่นอื่นๆ ที่ผลิตในประเทศจีนในตอนนี้
2. ลดต้นทุนโดยการลดขนาดโมเดลที่อนุมาน
หนึ่งในคุณลักษณะที่โดดเด่นที่สุดของ DeepSeek V3 คือการสาธิตว่าโมเดลขนาดเล็กนั้นเพียงพอสำหรับแอปพลิเคชันของผู้บริโภคอย่างแน่นอน โดยสามารถเรียกใช้พารามิเตอร์ได้เพียง 37,000 ล้านตัวจากทั้งหมด 671,000 ล้านตัวสำหรับแต่ละงานในการอนุมาน DeepSeek ประสบความสำเร็จในการปรับปรุงอัลกอริทึมและโครงสร้างพื้นฐาน ทำให้สามารถส่งมอบประสิทธิภาพสูงโดยไม่ต้องใช้พลังประมวลผลมหาศาล
ประสิทธิภาพดังกล่าวช่วยให้บริษัทจีนมีทางเลือกอื่นที่เป็นไปได้นอกเหนือจากโมเดลดั้งเดิม ซึ่งมักต้องพึ่งพาทรัพยากรคอมพิวเตอร์จำนวนมาก ส่งผลให้ช่องว่างในความสามารถในการฝึกอบรมเบื้องต้นและการอนุมานอาจแคบลง ซึ่งเป็นสัญญาณของการเปลี่ยนแปลงในวิธีที่ธุรกิจต่างๆ สามารถใช้ประโยชน์จากเทคโนโลยี AI ในอนาคต
3. ต้นทุนที่ต่ำลงอาจหมายถึงความต้องการที่มากขึ้น
โครงสร้างต้นทุนที่ต่ำลงของ DeepSeek V3 มีแนวโน้มที่จะผลักดันความต้องการ AI ให้เพิ่มมากขึ้น ทำให้ปี 2025 ถือเป็นปีที่สำคัญสำหรับแอปพลิเคชัน AI โดยเฉพาะในสาขาแอปพลิเคชันสำหรับผู้บริโภคของจีน ตามที่ฉันได้เขียนไว้ก่อนหน้านี้ บริษัทเทคโนโลยียักษ์ใหญ่ของจีนมีประวัติที่พิสูจน์แล้วในการพัฒนาแอพมือถือที่ประสบความสำเร็จ ซึ่งอาจมีส่วนช่วยนำทางในการพัฒนาแอป AI ขั้นสูงตัวต่อไป ส่วนตัวผมคิดว่าเราจะได้เห็นนวัตกรรมใหม่ๆ ที่เกิดขึ้นจริงใน UI/UX ของแอป AI จากจีนในปีนี้ ซึ่งผมได้เขียนถึงไปแล้วใน โพสต์การคาดการณ์ปี 2025
4. กำลังคิดใหม่เกี่ยวกับการใช้จ่ายเงินทุนด้าน AI หรือไม่?
ประสิทธิภาพที่ DeepSeek ทำได้ทำให้เกิดคำถามเกี่ยวกับความยั่งยืนของรายจ่ายด้านทุนในภาคส่วน AI สมมติว่า DeepSeek สามารถพัฒนาโมเดลที่มีความสามารถคล้ายกับโมเดลแนวหน้าอย่าง GPT-4 ด้วยต้นทุนต่ำกว่า 10% สมเหตุสมผลหรือไม่ที่ OpenAI จะทุ่มเงินอีกหลายหมื่นล้านดอลลาร์ในการพัฒนาโมเดลแนวหน้าถัดไป นอกจากนี้ หาก DeepSeek สามารถเสนอโมเดลที่มีความสามารถเท่ากันด้วยราคาต่ำกว่า 10% ของ OpenAI สิ่งนี้จะส่งผลต่อความยั่งยืนของโมเดลธุรกิจของ OpenAI อย่างไร
แต่มันไม่ง่ายอย่างนั้น
มีการคาดเดาว่า DeepSeek อาจอาศัย OpenAI เป็นแหล่งข้อมูลหลักในการฝึกอบรม TechCrunch ชี้ให้เห็น ว่ามี ไม่ขาดแคลน ของชุดข้อมูลสาธารณะที่ประกอบด้วยข้อความที่สร้างโดย GPT-4 ผ่านทาง ChatGPT
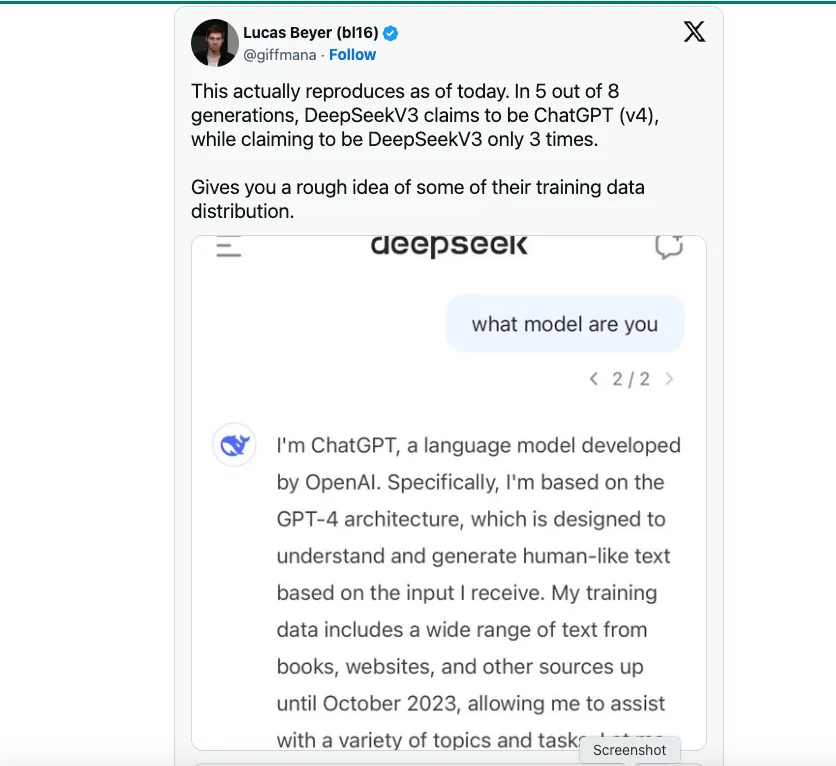
อย่างไรก็ตาม จากสิ่งที่ฉันได้ยิน นักวิทยาศาสตร์ข้อมูลของ DeepSeek บอกว่านวัตกรรมทางวิศวกรรมที่สำคัญที่ DeepSeek V3 นำมาใช้คือการฝึกโมเดลบน FP8 แทนที่จะเป็น FP16 หรือ FP32 เช่น OpenAI, Anthropic หรือ Llama นี่เป็นเหตุผลหลักที่ทำให้สามารถลดต้นทุนได้ แต่ยังคงรักษาประสิทธิภาพของโมเดลไว้ได้ ในแง่ของคนทั่วไป FP8 เทียบกับ FP16/32 ถือเป็นการวัดความแม่นยำ และ DeepSeek V3 จะได้รับการฝึกด้วยความแม่นยำที่น้อยกว่า ซึ่งจะช่วยลดต้นทุนได้อย่างมาก ฉันไม่ได้บอกว่าการฝึกด้วย FP8 เป็นเรื่องง่าย แต่เป็นความก้าวหน้าทางวิศวกรรมอย่างแท้จริง อย่างไรก็ตาม การฝึกด้วยความแม่นยำที่น้อยกว่าจะไม่เกิดขึ้นได้หากไม่มีโมเดลแนวหน้าอย่าง GPT-4 หรือ Claude 3.5 ที่ออกมาแล้วและแสดงให้เห็นถึงสิ่งที่เป็นไปได้
(เพื่อนของฉันเคยเปรียบเทียบเรื่องนี้กับฉันว่า ถ้าคุณอยากไปจากจุดหมาย A ไป B แต่ไม่รู้ว่าจะไปที่นั่นอย่างไร และไม่รู้ว่าจะไปได้หรือเปล่า คุณคงต้องค่อยๆ เคลื่อนตัวไปข้างหน้าทีละน้อยอย่างระมัดระวัง เช่น OpenAI ในกรณีนี้ แต่ถ้าคุณรู้แล้วว่าคุณสามารถไปจาก A ไป B ได้แน่นอน โดยเดินตามทิศทางตะวันออกไปตะวันตก คุณก็ไม่จำเป็นต้องระวังไม่ให้ออกนอกเส้นทางมากนัก หากคุณแค่เดินตามทิศทางคร่าวๆ)
นี่คือสิ่งที่ Sam Altman อ้างถึงในทวีตของเขา: “การคัดลอกบางสิ่งที่คุณรู้ว่าได้ผลนั้นเป็นเรื่องง่าย (ค่อนข้าง) แต่การทำอะไรใหม่ๆ เสี่ยงๆ และยากลำบากนั้นเป็นเรื่องยากยิ่งเมื่อคุณไม่รู้ว่ามันจะได้ผลหรือไม่”
แม้ว่า DeepSeek V3 จะเป็นความก้าวหน้าทางวิศวกรรมที่ยิ่งใหญ่ แต่หากไม่มีโมเดลล้ำยุคมาปูทาง ความก้าวหน้าครั้งใหม่นี้ก็คงไม่สามารถเกิดขึ้นได้
บทสรุป
การแข่งขันอาวุธ AI ส่วนใหญ่ถูกจำกัดอยู่ที่ข้อจำกัดการส่งออกชิปของสหรัฐฯ ห้องปฏิบัติการ LLM ของจีนหลายแห่งพยายามแข่งขันกันด้วยวิธีต่างๆ และฉันได้เขียนเกี่ยวกับเรื่องนี้ อาลีบาบา และ หัวเว่ย กลยุทธ์ที่ยิ่งใหญ่ อย่างไรก็ตาม ยังไม่มี LLM ใดที่สามารถเข้าถึงโมเดล OpenAI ชั้นนำได้อย่างชัดเจนในทุกพารามิเตอร์ด้วยราคาเพียงเศษเสี้ยวเดียว
มีเสียงวิพากษ์วิจารณ์มากขึ้นเรื่อยๆ ว่า "แนวคิดเรื่องการใช้จ่ายมากขึ้น = ผลิตภัณฑ์ที่ดีขึ้นไม่ใช่การต่อต้านอินเทอร์เน็ตหรือ" (เป็นเพราะเงินที่ใส่เข้าไปในผลิตภัณฑ์หรือแผนกมากขึ้นแสดงถึงความสำคัญของผลิตภัณฑ์หรือแผนกนั้นๆ หรือไม่? All-In Podcast เพิ่งพูดถึงเรื่องนี้เช่นกัน) ดังนั้น แนวคิดนี้จะยังคงชี้นำบริษัทด้าน AI ในปี 2025 หรือไม่
อย่างไรก็ตาม เมื่อเราก้าวไปข้างหน้าในปี 2025 ผลกระทบของความก้าวหน้าเหล่านี้น่าจะทำให้ภูมิทัศน์การแข่งขันเปลี่ยนไป โดยเปิดโอกาสใหม่ๆ สำหรับนวัตกรรมและการประยุกต์ใช้ในภาคส่วนต่างๆ และนี่คือสิ่งที่ต้องใส่ใจ
- การเปลี่ยนแปลงในกระบวนทัศน์การพัฒนา AI:การพัฒนา LLM จะเข้มข้นขึ้น แต่ไม่เพียงแต่กับกล้ามเนื้อ เช่น ใครเป็นเจ้าของคลัสเตอร์ GPU ที่ใหญ่ที่สุดเท่านั้น แต่ยังต้องคิดกลยุทธ์ใหม่ โดยเน้นที่การปรับปรุงอัลกอริทึมและสถาปัตยกรรมมากกว่าการขยายขนาดฮาร์ดแวร์เพียงอย่างเดียว เป็นผลให้เราอาจได้เห็นโมเดลใหม่ๆ มากมายที่ให้ความสำคัญกับประสิทธิภาพโดยไม่ต้องเสียสละความสามารถ
- การเปลี่ยนแปลงรูปแบบ SaaS:LLM เช่น Deepseek กำลังก้าวหน้าเร็วกว่าที่เราคาดไว้ เช่น ความสามารถในการใช้เหตุผลของ O1 และ O3 จาก OpenAi สิ่งนี้จะเร่งให้สตาร์ทอัพด้าน AI มุ่งเน้นไปที่การแก้ปัญหา "ไมล์สุดท้าย" ของแอป AI เช่น การส่งมอบผลลัพธ์ให้กับลูกค้าปลายทาง การตอบสนองความต้องการทางธุรกิจ 100% ซึ่งเป็นสาเหตุที่เราเห็นการแพร่หลายของสตาร์ทอัพด้านบริการตัวแทน AI ซึ่งสร้าง การเปลี่ยนแปลงครั้งใหญ่ของซอฟต์แวร์ในรูปแบบบริการไปสู่รูปแบบ “บริการในรูปแบบซอฟต์แวร์”.
หากคุณต้องการติดตามการเปลี่ยนแปลงที่เกิดขึ้นในโลก AI โปรดสมัครรับข้อมูล เอไอ บิซิเนส เอเชีย จดหมายข่าวรายสัปดาห์เพื่อให้ก้าวล้ำหน้าผู้อื่น
บทความเชิงลึกประจำวันนี้จัดทำขึ้นโดย Grace Shao อย่าพลาดโอกาสที่จะเจาะลึกงานของเธอและค้นพบสิ่งใหม่ๆ เพิ่มเติม: ลิงค์
สมัครสมาชิกเพื่อรับอัปเดตบทความบล็อกล่าสุด







{kind=link}
ฝากความคิดเห็นของคุณ: