
O Deepseek-V3 rendeu ao China LLM um headset do LLM Club.
O lançamento recente do modelo V3 da DeepSeek causou repercussões no cenário da IA, mesmo que sua iteração anterior, R1, já tivesse começado a capturar a atenção no Ocidente. Apoiado por um dos principais fundos quantitativos da China, o High-Flyer, que ostenta um AUM estimado de $5,5 a $8 bilhões, a DeepSeek alcançou um desempenho de modelo notável com uma fração do custo de treinamento normalmente necessário.
Por exemplo, de acordo com Andrej Karpathy, ex-chefe de IA da Tesla e um dos cofundadores da OpenAI, o Llama 3-405B da Meta usou 30,8 milhões de horas de GPU, enquanto o DeepSeek-V3 parece ser um modelo mais forte com apenas 2,8 milhões de horas de GPU, 11x menos computação. Esta é uma exibição altamente impressionante de pesquisa e engenharia sob restrições de recursos.
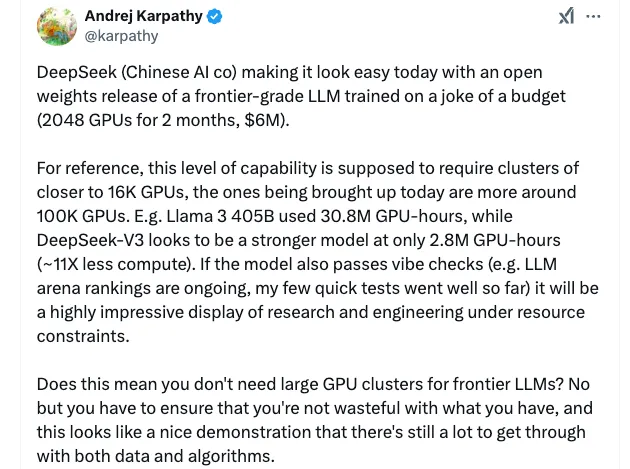
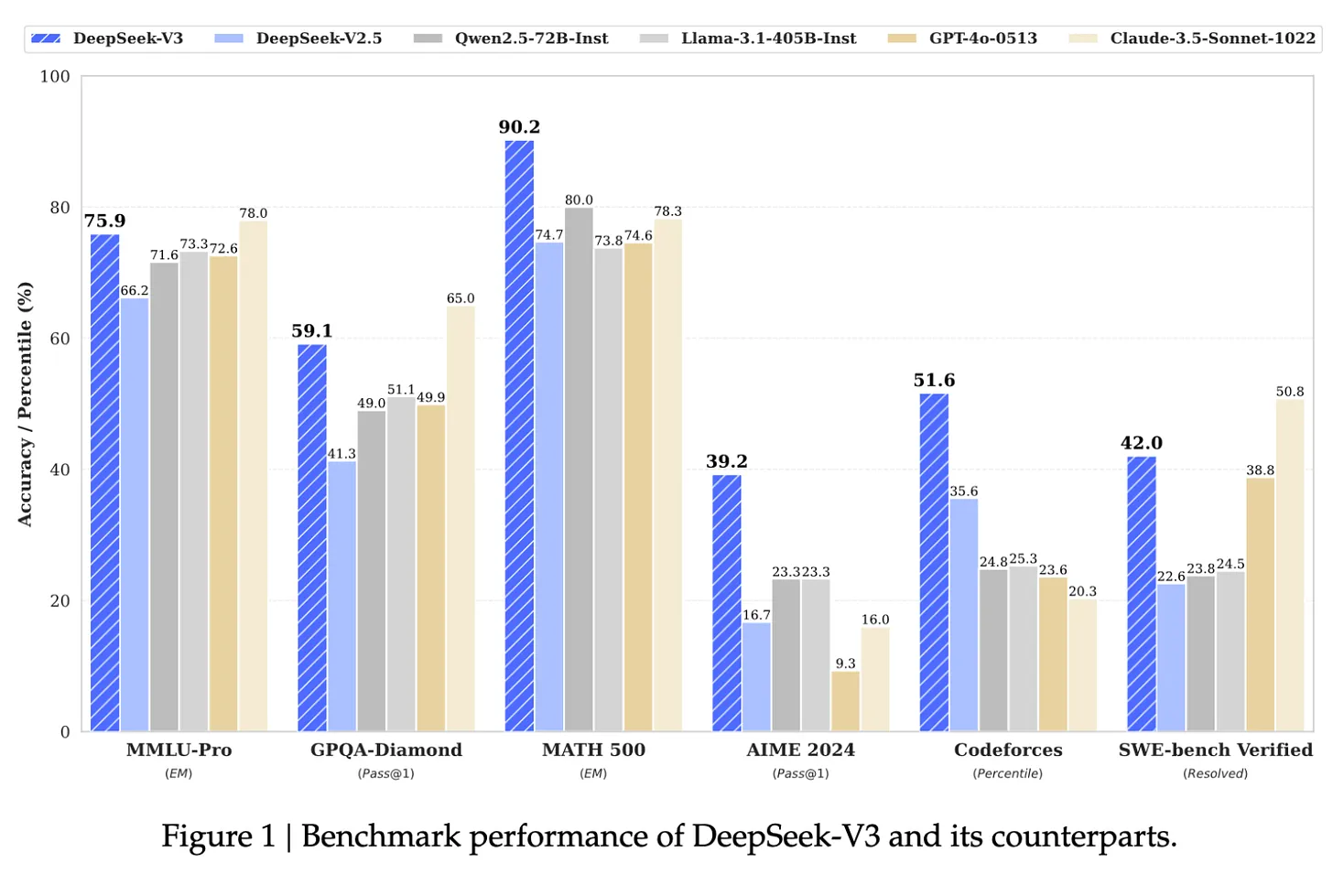
Fonte: Artigo DeepSeek-V3
Além dos comentários de Andrej Karparthy, o burburinho em torno do DeepSeek-V3 tem sido palpável em plataformas como Twitter/X, onde Sam Altman (CEO da OpenAI), Alexandr Wang (CEO da Scale AI) e Jim Fan (cientista sênior de pesquisa da NVIDIA) se envolveram em discussões sobre suas implicações. Enquanto alguns pareciam impressionados com o avanço, outros, como Sam Altman, expressaram ceticismo sobre as inovações do DeepSeek.
Quem é DeepSeek?
Ao contrário de muitas de suas contrapartes chinesas — frequentemente chamadas de "quatro tigres da IA" (Minimax, Moonshot, Baichuan, Zhipu AI) — que contam com arrecadação significativa de fundos de grandes empresas de tecnologia, a DeepSeek é totalmente financiada pela High-Flyer e manteve um perfil discreto até seu recente avanço.
Em maio de 2024, a DeepSeek introduziu um modelo de código aberto chamado DeepSeek V2, que ostentava uma relação custo-desempenho excepcional. O custo da computação de inferência era de apenas 1 yuan por milhão de tokens — aproximadamente um sétimo do Meta Llama 3.1 e um septuagésimo do GPT-4 Turbo.
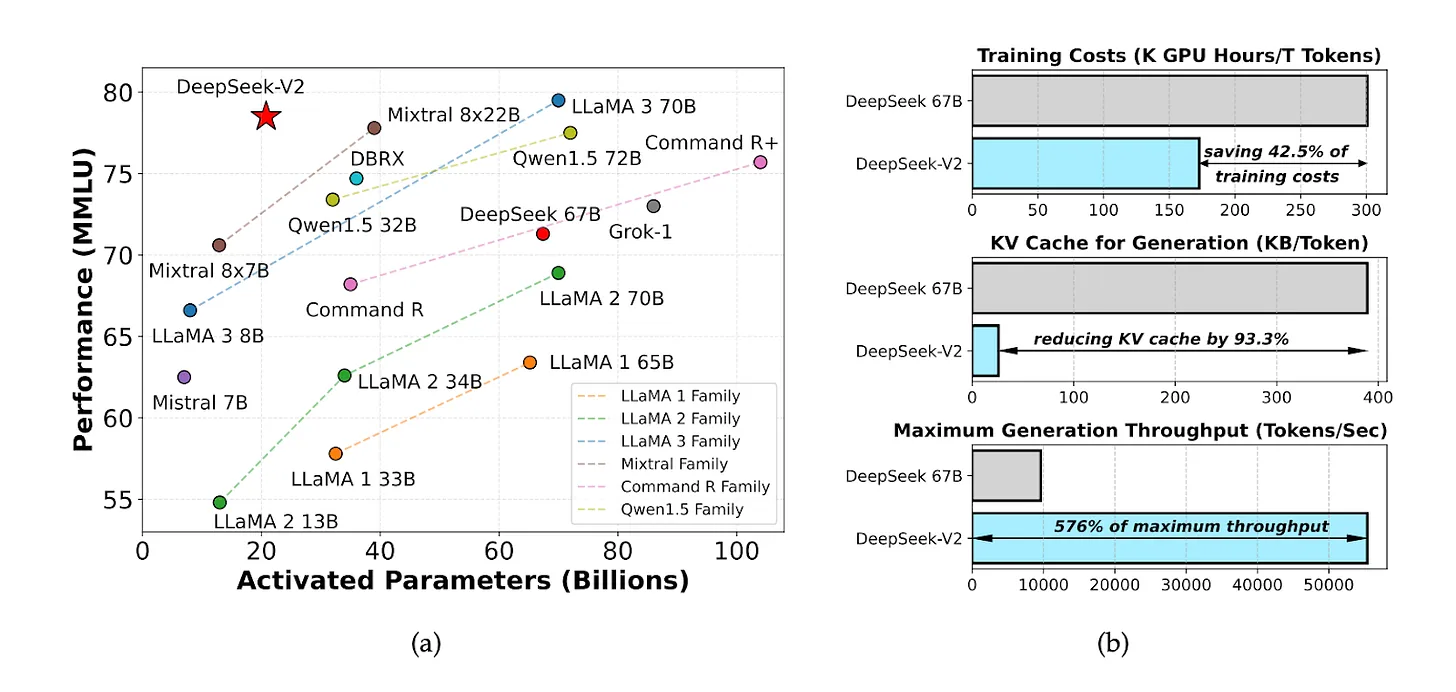
Fonte: Artigo DeepSeek-V2
Essa estratégia de preços desencadeou uma guerra de preços no grande mercado de modelos de linguagem da China, e muitos foram rápidos em comparar o DeepSeek ao Pinduoduo (PDD) por seu impacto disruptivo na dinâmica de preços (para contextualizar, o PDD é o disruptor de menor custo no comércio eletrônico na China).
Em julho passado, o China Talk de Jordan Schneider traduziu uma longa entrevista entre o fundador da empresa, Liang Wenfeng, e a publicação de tecnologia chinesa 36kr. Você pode encontrar a entrevista aqui. Foi um dos poucos compromissos de mídia que a empresa teve.
Uma pequena anedota engraçada da entrevista que se destacou para mim:
// O fundador pós-anos 80, que tem trabalhado nos bastidores com tecnologia desde a era High-Flyer, continua seu estilo discreto na era DeepSeek — "lendo artigos, escrevendo códigos e participando de discussões em grupo" 看论文, 写代码, publicando artigos todos os dias, assim como qualquer outro pesquisador faz.
Ao contrário de muitos fundadores de fundos quantitativos — que têm experiência em fundos de hedge no exterior e diplomas em física ou matemática — Liang Wenfeng sempre manteve uma formação local: em seus primeiros anos, ele estudou inteligência artificial no Departamento de Engenharia Elétrica da Universidade de Zhejiang.//
Isso dá muita cor ao DeepSeek, um contraste gritante com muitas das startups de IA mais famintas por mídia no espaço agora. Liang parece tão focado em apenas "fazer acontecer".
Ouvi falar da empresa pela primeira vez há quase seis meses, e a maneira como as pessoas falavam sobre ela era: "É tão secreta; está fazendo um trabalho inovador, mas ninguém sabe muito mais sobre ela". A DeepSeek já foi chamada até mesmo de "a força misteriosa do Leste" no Vale do Silício, supostamente.
Mesmo durante a entrevista de julho (antes do lançamento do V3), o CEO da DeepSeek, Liang Wenfeng, disse que muitos ocidentais estão (ficarão) simplesmente surpresos ao ver a inovação surgir de uma empresa chinesa e horrorizados ao ver empresas chinesas se destacando como inovadoras em vez de meras seguidoras. Que prenúncio do frenesi que estamos vendo em torno do lançamento do V3 agora.
Desempenho e velocidade do modelo V3
O DeepSeek V3 é um feito impressionante em termos de velocidade e escala. Operando a 60 tokens por segundo, ele é três vezes mais rápido que seu antecessor, o DeepSeek V2. Esse aumento de velocidade é crucial para aplicativos em tempo real e tarefas de processamento complexas.
Com 671 bilhões de parâmetros, o DeepSeek V3 se destaca como o maior modelo de linguagem de código aberto disponível hoje (maior até do que o do Meta Llama 3, que é de cerca de 400 bilhões). Essa extensa contagem de parâmetros contribui significativamente para sua compreensão e capacidades de geração diferenciadas.
Inovações arquitetônicas
O DeepSeek V3 apresenta diversas inovações arquitetônicas importantes que o diferenciam dos concorrentes (com a ajuda da Perplexity):
- Arquitetura de mistura de especialistas (MoE):
O modelo emprega uma arquitetura MoE sofisticada que ativa apenas uma fração de seus parâmetros totais durante o processamento. Embora ostente 671 bilhões de parâmetros, ele envolve apenas 37 bilhões para cada tarefa. Essa ativação seletiva permite alto desempenho sem a carga computacional tipicamente associada a modelos tão grandes. - Atenção Latente Multi-Cabeça (MLA):
O DeepSeek V3 apresenta um mecanismo MLA que comprime representações de chave-valor, reduzindo significativamente os requisitos de memória, mantendo a qualidade. Esse processo de compressão de dois estágios gera um vetor latente comprimido que captura informações essenciais, que podem ser projetadas de volta para espaços de chave e valor, conforme necessário. - Balanceamento de carga sem perdas auxiliares:
O modelo introduz uma estratégia inovadora de balanceamento de carga que evita perdas auxiliares tradicionais que podem prejudicar o desempenho. Em vez disso, ele emprega termos de viés dinâmico para cada especialista com base na utilização durante o treinamento, garantindo distribuição eficiente da carga de trabalho sem comprometer o desempenho geral. - Previsão de múltiplos tokens (MTP):
O MTP permite que o DeepSeek V3 gere vários tokens simultaneamente em vez de um por vez. Essa capacidade acelera drasticamente os tempos de inferência e melhora a eficiência geral na geração de respostas, o que é especialmente crítico para tarefas que exigem geração rápida de saída.
Implicações potenciais
As maiores conclusões que obtive sobre este modelo V3 são:
1. Experiência do consumidor muito melhor
Sua versatilidade permite que ele se destaque em muitos casos de uso diferentes. Ele pode elaborar ensaios, e-mails e outras formas de comunicação escrita com alta precisão e oferece fortes recursos de tradução em vários idiomas. Um amigo que o tem usado nos últimos dias disse que sua saída é muito semelhante à qualidade do Gemini e do ChatGPT, uma experiência melhor do que outros modelos feitos na China atualmente.
2. Redução de custos por meio da redução do tamanho do modelo na inferência
Um dos aspectos mais marcantes do DeepSeek V3 é sua demonstração de que modelos menores podem ser inteiramente suficientes para aplicações de consumo. Ele é capaz de envolver apenas 37 bilhões de 671 bilhões de parâmetros para cada tarefa na inferência. O DeepSeek se destacou na otimização de seus algoritmos e infraestrutura, permitindo que ele entregasse alto desempenho sem precisar de poder de computação massivo.
Essa eficiência fornece às empresas chinesas uma alternativa viável aos modelos tradicionais, que frequentemente dependem muito de recursos computacionais extensivos. Como resultado, a lacuna em capacidades de pré-treinamento e inferência pode estar diminuindo, sinalizando uma mudança em como as empresas podem alavancar a tecnologia de IA no futuro.
3. Custo mais baixo provavelmente significa mais demanda
A estrutura de custo mais baixo do DeepSeek V3 provavelmente impulsionará ainda mais a demanda por IA, tornando 2025 um ano crucial para aplicações de IA. Especialmente no campo de aplicações de consumo da China, como já escrevi antes, as grandes empresas de tecnologia chinesas têm um histórico comprovado no desenvolvimento de aplicativos móveis matadores, que pode servir como uma vantagem para liderar o caminho no desenvolvimento do próximo super aplicativo de IA. Pessoalmente, acho que veremos alguma inovação real na IU/UX de aplicativos de IA da China este ano, sobre a qual escrevi em meu Postagem de previsões para 2025.
4. Repensando os gastos de capital em IA?
A eficiência alcançada pela DeepSeek levanta questões sobre a sustentabilidade dos gastos de capital no setor de IA. Suponha que a DeepSeek possa desenvolver modelos com capacidades semelhantes a modelos de fronteira como GPT-4 por menos de 10% do custo. Faz sentido para a OpenAI investir dezenas de bilhões de dólares a mais no desenvolvimento do próximo modelo de fronteira? Além disso, se a DeepSeek pode oferecer modelos com as mesmas capacidades por menos de 10% do preço da OpenAI, o que isso significa para a viabilidade do modelo de negócios da OpenAI?
Mas não é tão simples assim.
Houve especulações de que o DeepSeek pode ter confiado no OpenAI como fonte primária para seus dados de treinamento. TechCrunch aponta que existe sem escassez de conjuntos de dados públicos contendo texto gerado pelo GPT-4 via ChatGPT.
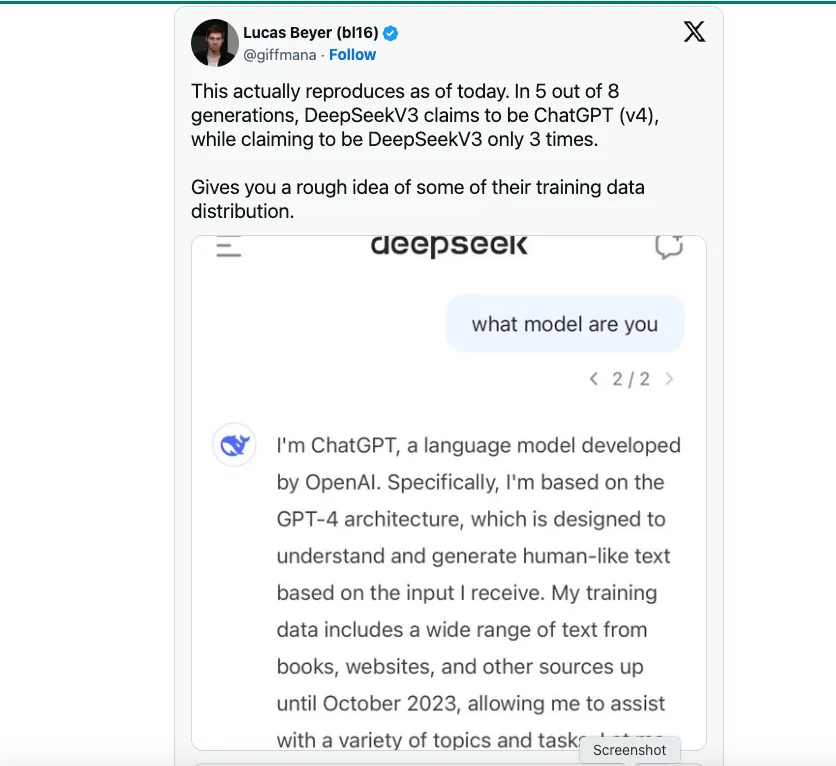
No entanto, pelo que ouvi, um cientista de dados do DeepSeek disse que uma inovação de engenharia fundamental adotada pelo DeepSeek V3 é treinar o modelo no FP8 em vez do FP16 ou FP32, como OpenAI, Anthropic ou Llama. Esta é a principal razão pela qual foi possível cortar custos e ainda assim atingir a proeza do modelo. Em termos leigos, FP8 vs. FP16/32 é uma medida de precisão, e o DeepSeek V3 é treinado com menos precisão, o que reduz significativamente o custo. Não estou dizendo que treinar no FP8 é uma tarefa fácil; é totalmente um avanço da engenharia. No entanto, treinar com menos precisão não seria possível se não houvesse modelos de fronteira como GPT-4 ou Claude 3.5 que já tivessem sido lançados e mostrado o que era possível.
(Uma metáfora que meu amigo usou para me explicar isso é assim: se você quisesse ir do destino A para B, mas não tivesse ideia de como chegar lá e se é possível alcançá-lo, você teria sido muito cuidadoso, avançando aos poucos, ou seja, OpenAI neste caso. Mas se você já sabe que pode definitivamente ir de A para B seguindo uma direção geral de Leste para Oeste, então você não precisaria ser tão cauteloso em sair dos trilhos se apenas seguisse a direção aproximada.)
Foi a isso que Sam Altman se referiu em seu tweet: “É (relativamente) fácil copiar algo que você sabe que funciona. É extremamente difícil fazer algo novo, arriscado e complicado quando você não sabe se vai funcionar.”
Embora o DeepSeek V3 seja um avanço da engenharia, sem os modelos de ponta abrindo caminho, esse novo avanço não teria sido possível.
Conclusão
A narrativa da corrida armamentista da IA foi amplamente limitada às restrições de exportação de chips dos EUA. Vários laboratórios LLM chineses tentaram competir de várias maneiras, e eu escrevi sobre Alibaba e Da Huawei grandes estratégias. Ainda assim, nenhum LLM realmente conseguiu atingir o modelo OpenAI líder tão descaradamente em todos os parâmetros por uma fração do preço.
Mais e mais vozes estão dizendo: "A ideia de mais gastos = melhor produto não é anti-internet?" (Será que é porque mais dinheiro investido em um produto ou departamento simboliza sua importância? O All-In Podcast também discutiu isso recentemente.) Então, essa ideia ainda guiará as empresas de IA em 2025?
No entanto, à medida que avançamos em 2025, as implicações desses avanços provavelmente remodelarão o cenário competitivo, oferecendo novas oportunidades para inovação e aplicação em vários setores. E aqui o que prestar atenção
- A mudança nos paradigmas de desenvolvimento da IA: O desenvolvimento de LLM se intensificará, mas não apenas nos músculos, por exemplo, quem possui os maiores clusters de GPU, em vez de repensar estratégias, focando na otimização de algoritmos e arquiteturas em vez de apenas aumentar a escala do hardware. Como resultado, podemos testemunhar uma onda de novos modelos que priorizam a eficiência sem sacrificar a capacidade
- A mudança do modelo SaaS: LLM como Deepseek estão avançando mais rápido do que antecipamos, por exemplo, a capacidade de raciocínio de O1 e O3 da OpenAi. Isso acelerará mais startups de IA a se concentrarem na solução do Desafio da “última milha” dos aplicativos de IA, por exemplo, entregando resultados ao cliente final, atendendo a 100% de requisitos de negócios, razão pela qual vemos a proliferação de startups de serviços de agentes de IA. O que cria Mudança de paradigma de software como serviço para “serviço como software”.
Se você quiser ficar por dentro das mudanças que estão ocorrendo no mundo da IA, assine o Negócios de IA na Ásia boletim semanal para ficar à frente das novidades.
O artigo perspicaz de hoje é trazido a você por Grace Shao. Não perca a oportunidade de mergulhar mais fundo em seu trabalho e descobrir mais: Link
Inscreva-se para receber atualizações sobre as últimas postagens do blog
Você também pode gostar








{kind=link}
Deixe seu comentário: