
Deepseek-V3 earns China LLM a headset of LLM Club.
DeepSeek’s recent launch of its V3 model has sent ripples through the AI landscape, even as its earlier iteration, R1, had already begun to capture attention in the West. Backed by one of China’s leading quantitative funds, High-Flyer, which boasts an estimated AUM of $5.5 to $8 billion, DeepSeek has achieved remarkable model performance with a fraction of the training cost typically required.
For instance, according to Andrej Karpathy, former AI head of Tesla and one of the co-founders of OpenAI, Meta’s Llama 3-405B used 30.8 million GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8 million GPU-hours, 11x less compute. This is a highly impressive display of research and engineering under resource constraints.
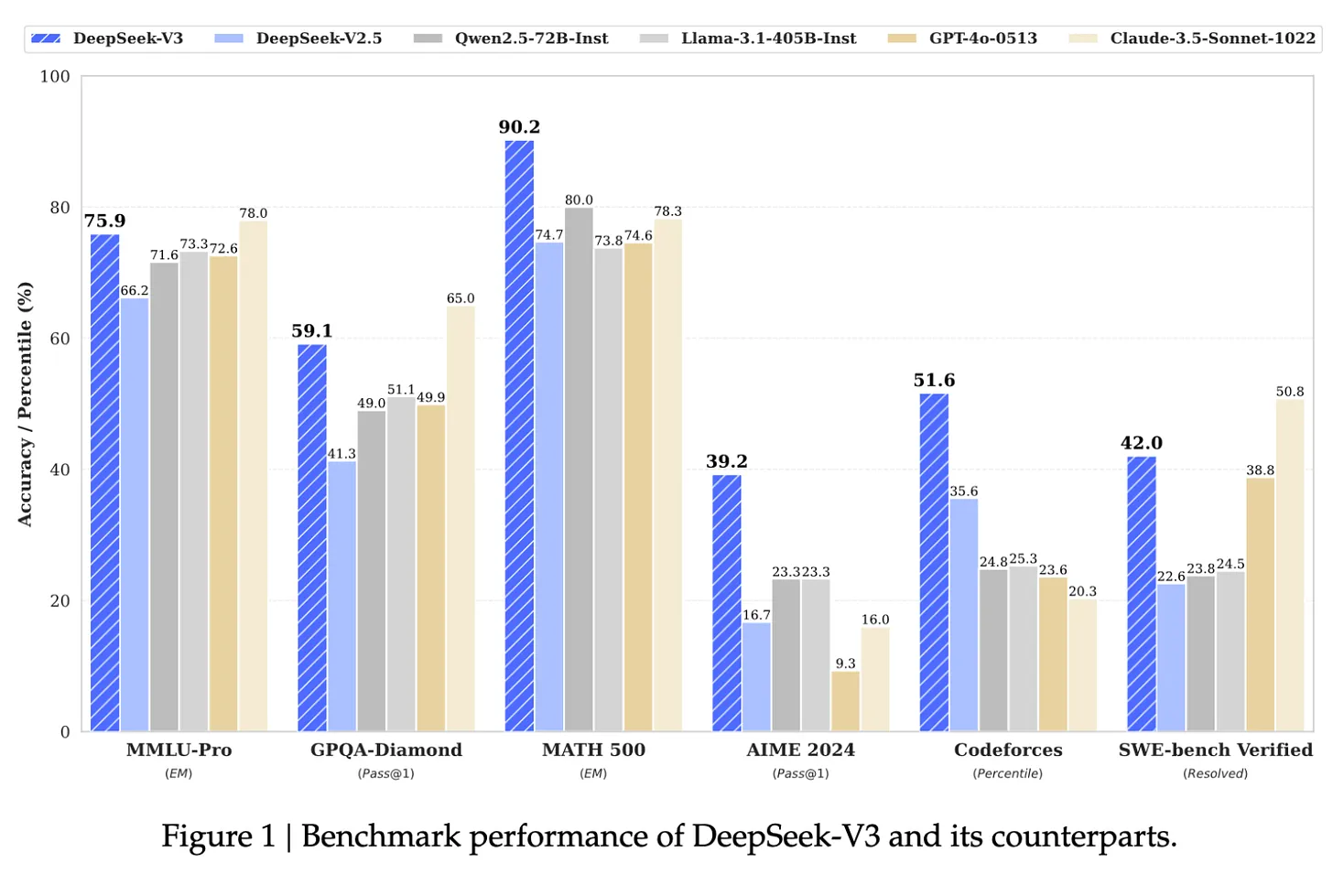
Source: DeepSeek-V3 paper
Beyond Andrej Karparthy’s comments, the buzz surrounding DeepSeek-V3 has been palpable on platforms like Twitter/X, where Sam Altman (CEO of OpenAI), Alexandr Wang (CEO of Scale AI) and Jim Fan (Senior Research Scientist at NVIDIA) have engaged in discussions about its implications. While some seemed to be impressed by the breakthrough, others, like Sam Altman, expressed skepticism about DeepSeek’s innovations.
Who is DeepSeek?
Unlike many of its Chinese counterparts—often referred to as the “AI four tigers” (Minimax, Moonshot, Baichuan, Zhipu AI)—which have relied on significant fundraising from major tech companies, DeepSeek is fully funded by High-Flyer and maintained a low profile until its recent breakthrough.
In May 2024, DeepSeek introduced an open-source model named DeepSeek V2, which boasted an exceptional cost-performance ratio. The inference computing cost was just 1 yuan per million tokens—approximately one-seventh that of Meta Llama 3.1 and one-seventieth that of GPT-4 Turbo.
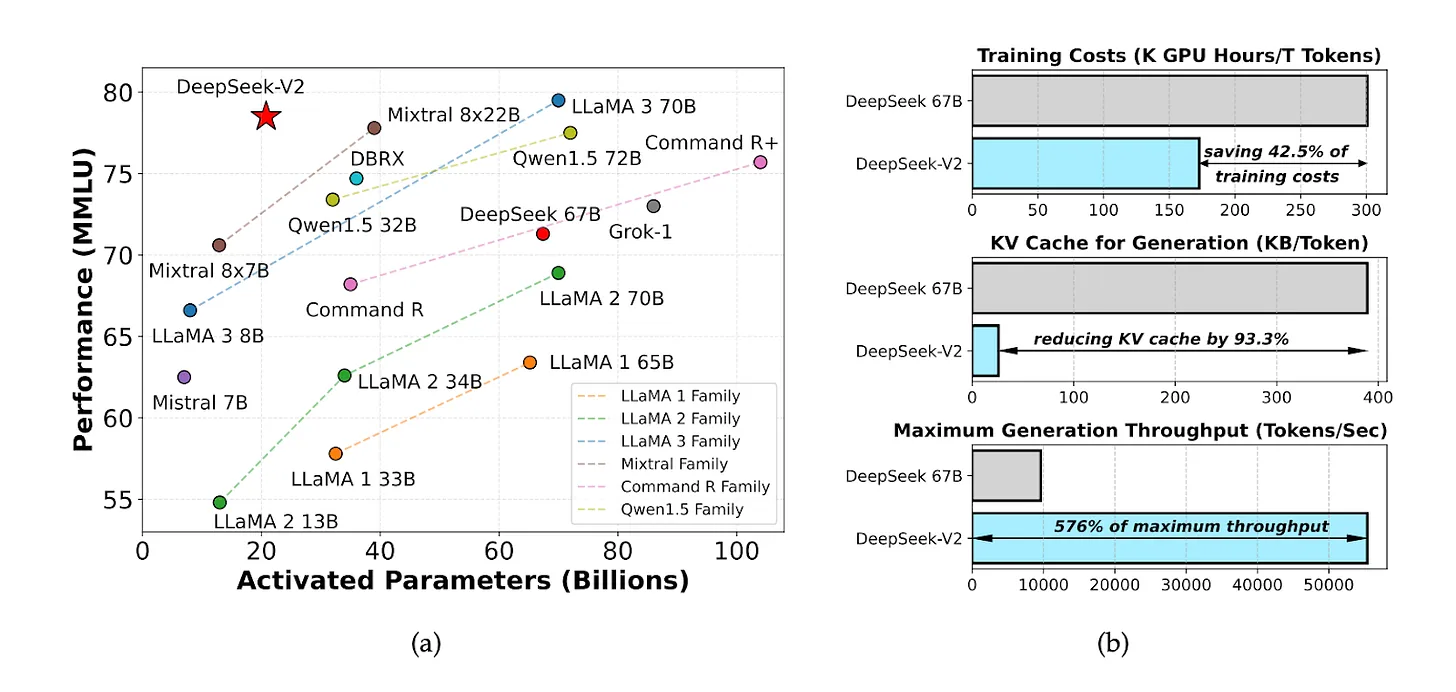
Source: DeepSeek-V2 Paper
This pricing strategy triggered a price war in China’s large language model market, and many were quick to liken DeepSeek to Pinduoduo (PDD) for its disruptive impact on pricing dynamics (for context, PDD is the lower cost disruptor in e-commerce in China).
Last July, Jordan Schneider’s China Talk translated a lengthy interview between the company’s founder, Liang Wenfeng, and the Chinese tech publication 36kr. You can find the interview here. It was one of the very few media engagements the company had.
A funny little anecdote from the interview that stood out for me:
// The post-80s founder, who has been working behind the scenes on technology since the High-Flyer era, continues his low-key style in the DeepSeek era — “reading papers, writing code, and participating in group discussions” 看论文,写代码,参与小组讨论 every day, just like every other researcher does.
Unlike many quant fund founders — who have overseas hedge-fund experience and physics or mathematics degrees — Liang Wenfeng has always maintained a local background: in his early years, he studied artificial intelligence at Zhejiang University’s Department of Electrical Engineering.//
This provides a lot of color for DeepSeek, a stark contrast to many of the more media-hungry AI startups in the space right now. Liang seems so focused on just “getting it done.”
I first heard of the company nearly six months ago, and the way people talked about it was, “It’s so secretive; it’s doing groundbreaking work, but no one knows much more about it.” DeepSeek has even been referred to as “the mysterious force from the East” 来自东方的神秘力量 in Silicon Valley, supposedly.
Even during the July interview (before V3’s release), DeepSeek’s CEO Liang Wenfeng said many Westerners are (will be) simply surprised to see innovation stem from a Chinese company and at ghast seeing Chinese firms stepping up as innovators rather than merely followers. What a foreshadow of the frenzy we’re seeing around the V3 release now.
The V3 Model Performance and Speed
DeepSeek V3 is an impressive feat in terms of both speed and scale. Operating at 60 tokens per second, it is three times faster than its predecessor, DeepSeek V2. This speed enhancement is crucial for real-time applications and complex processing tasks.
With 671 billion parameters, DeepSeek V3 stands as the largest open-source language model available today (even larger than Meta Llama 3’s, which is around 400 billion). This extensive parameter count contributes significantly to its nuanced understanding and generation capabilities.
Architectural Innovations
DeepSeek V3 introduces several key architectural innovations that set it apart from competitors (with help from Perplexity):
- Mixture-of-Experts (MoE) Architecture:
The model employs a sophisticated MoE architecture that activates only a fraction of its total parameters during processing. While it boasts 671 billion parameters, it engages only 37 billion for each task. This selective activation allows for high performance without the computational burden typically associated with such large models. - Multi-Head Latent Attention (MLA):
DeepSeek V3 features an MLA mechanism that compresses key-value representations, significantly reducing memory requirements while maintaining quality. This two-stage compression process generates a compressed latent vector that captures essential information, which can be projected back into key and value spaces as needed. - Auxiliary-Loss-Free Load Balancing:
The model introduces an innovative load-balancing strategy that avoids traditional auxiliary losses that can hinder performance. Instead, it employs dynamic bias terms for each expert based on utilization during training, ensuring efficient workload distribution without compromising overall performance. - Multi-Token Prediction (MTP):
MTP enables DeepSeek V3 to generate multiple tokens simultaneously rather than one at a time. This capability dramatically speeds up inference times and enhances overall efficiency in generating responses, which is especially critical for tasks requiring rapid output generation.
Potential Implications
The biggest takeaways I’ve gathered around this V3 model are:
1. Much better consumer experience
Its versatility allows it to excel across many different use cases. It can craft essays, emails, and other forms of written communication with high accuracy and offers strong translation capabilities across multiple languages. A friend who has been using it over the last few days said that its output is very similar to the quality of Gemini and ChatGPT, a better experience than other Chinese-made models right now.
2. Lowering cost through reducing model size at inference
One of the most striking aspects of DeepSeek V3 is its demonstration that smaller models can be entirely sufficient for consumer applications. It is able to engage only 37 billion out of 671 billion parameters for each task at inference. DeepSeek has excelled in optimizing its algorithms and infrastructure, allowing it to deliver high performance without needing massive computing power.
This efficiency provides Chinese companies with a viable alternative to traditional models, which often depend heavily on extensive computational resources. As a result, the gap in pre-training and inference capabilities may be narrowing, signaling a shift in how businesses can leverage AI technology in the future.
3. Lower cost probably means more demand
DeepSeek V3’s lower cost structure is likely to drive AI demand further, making 2025 a pivotal year for AI applications. Especially in China’s consumer-application field, as I’ve written about before, Chinese big tech has a proven track record in developing killer mobile apps, which may serve as an edge in leading the way in developing the next super AI app. Personally, I think we’ll see some real innovation in AI app UI/UX from China this year, which I wrote about in my 2025 predictions post.
4. Rethinking AI capital expenditure?
The efficiency achieved by DeepSeek raises questions about the sustainability of capital expenditures in the AI sector. Suppose DeepSeek can develop models with capabilities similar to frontier models like GPT-4 at less than 10% of the cost. Does it make sense for OpenAI to pour tens of billions of dollars more into developing the next frontier model? Also, if DeepSeek can offer models with the same capabilities at less than 10% of the price of OpenAI, what does this mean for OpenAI’s business model viability?
But it’s not that simple.
There has been speculation that DeepSeek may have relied on OpenAI as a primary source for its training data. TechCrunch points out that there is no shortage of public datasets containing text generated by GPT-4 via ChatGPT.
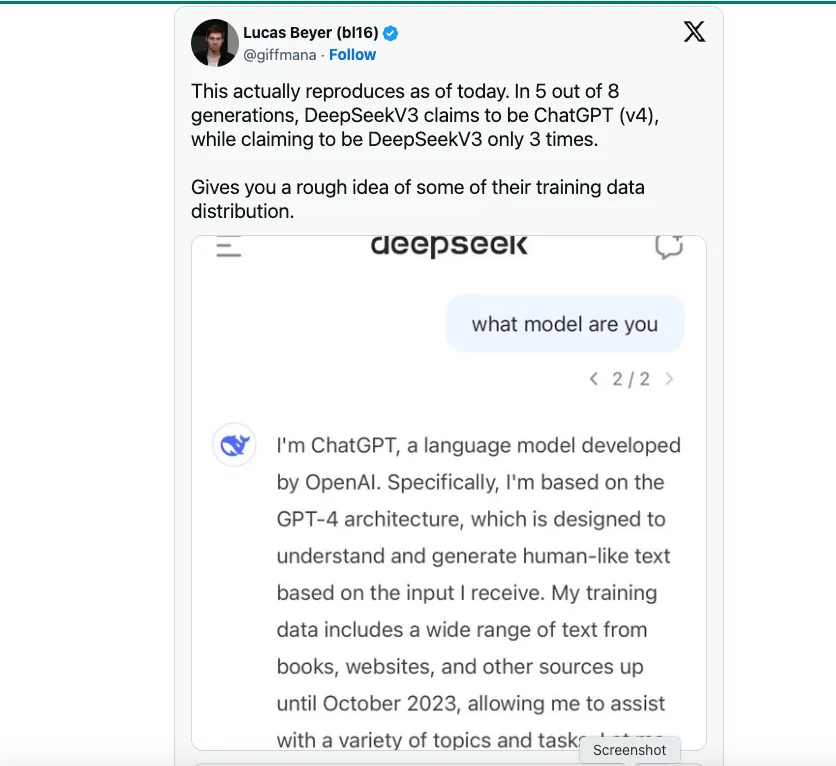
However, from what I heard, a DeepSeek data scientist said that a key engineering innovation that DeepSeek V3 adopted is training the model on FP8 rather than FP16 or FP32, like OpenAI, Anthropic, or Llama. This is the main reason it was able to cut costs yet still achieve the model prowess.In layman’s terms, FP8 vs. FP16/32 is a measurement of accuracy, and DeepSeek V3 is trained with less accuracy, which significantly reduces cost. I am not saying training on FP8 is an easy feat; it is totally an engineering breakthrough. However, training with less accuracy would not be possible if there were no frontier models like GPT-4 or Claude 3.5 that had already come out and showed what was possible.
(A metaphor my friend used to explain this to me is like this- if you wanted to get from destination A to B but had no idea how to get there and whether it is even possible to reach, you would have been very careful inching bit by bit forward, i.e., OpenAI in this case. But if you already know you can definitely get from A to B following a general direction of East to West, then you wouldn’t need to be as wary of going off rails if you just follow the rough direction.)
This is what Sam Altman was referring to in his tweet: “It is (relatively) easy to copy something that you know works. it is extremely hard to do something new, risky, and difficult when you don’t know if it will work.”
Even though DeepSeek V3 is an engineering breakthrough, without frontier models paving the way, this new breakthrough would not have been possible.
Conclusion
The AI arms race narrative has largely been capped at U.S. chip export restrictions. Various Chinese LLM labs have tried to compete in various ways, and I’ve written about Alibaba and Huawei’s grand strategies. Still, no LLM has really been able to reach the leading OpenAI model so blatantly across parameters at a fraction of the price.
More and more voices are saying, “Isn’t the idea of more spending = better product anti-internet?” (Is it because more money put into a product or department symbolizes its importance? All-In Podcast recently discussed this, too.) So, will this idea still guide AI companies in 2025?
Nonetheless, as we move forward in 2025, the implications of these advancements will likely reshape the competitive landscape, offering fresh opportunities for innovation and application across various sectors. And here what to pay attention to
- The Shift in AI Development Paradigms: LLM development will intensify but not only on muscles e.g. who owns biggest GPU clusters rather to rethink strategies, focusing on optimizing algorithms and architectures rather than merely scaling up hardware. As a result, we may witness a wave of new models that prioritize efficiency without sacrificing capability
- The shift of SaaS model: LLM such as Deepseek are advancing faster than we anticipate, e.g. the reasoning capability of O1 and O3 from OpenAi. This will accelerate more AI startups to focus on solving the “last mile” Challenge of AI apps, e.g. delivering results to the end customer, meeting 100% of business requirement, which is why we see the proliferation of AI agentic services startups. Which creates Paradigm shift of software-as-a-service to “service-as-a-software”.
If you want to keep tabs on the shifts taking place in the AI world, subscribe to the AI Business Asia weekly newsletter to stay ahead of the curve.
Today’s insightful article is brought to you by Grace Shao. Don’t miss the opportunity to dive deeper into her work and discover more: Link
Subscribe To Get Update Latest Blog Post




{kind=link}
Leave Your Comment: