
Deepseek-V3로 중국 LLM에 LLM Club의 헤드셋 자격을 부여했습니다.
DeepSeek의 최근 V3 모델 출시는 AI 분야에 파장을 일으켰지만, 이전 버전인 R1은 이미 서구에서 주목을 받기 시작했습니다. 중국 최고의 양적 펀드 중 하나인 High-Flyer의 지원을 받아 $5.5~$80억의 AUM을 자랑하는 DeepSeek은 일반적으로 필요한 훈련 비용의 일부로 놀라운 모델 성능을 달성했습니다.
예를 들어, Tesla의 전 AI 책임자이자 OpenAI의 공동 창립자 중 한 명인 Andrej Karpathy에 따르면 Meta의 Llama 3-405B는 3,080만 GPU 시간을 사용한 반면 DeepSeek-V3는 280만 GPU 시간으로 더 강력한 모델로 보이며 컴퓨팅은 11배 적습니다. 이는 리소스 제약 하에서 연구와 엔지니어링을 매우 인상적으로 보여줍니다.
원천: DeepSeek-V3 논문
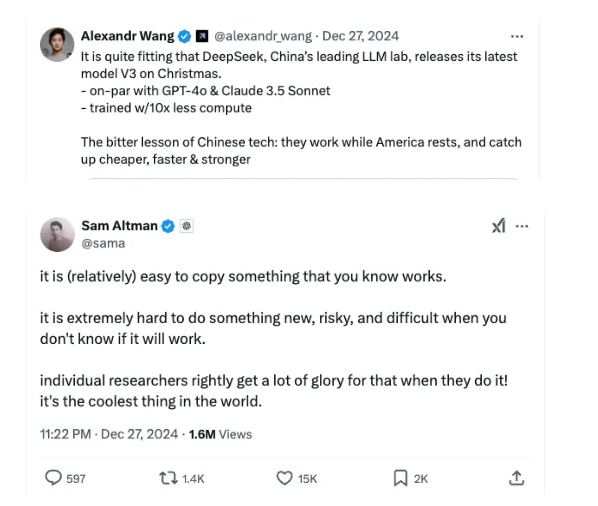
Andrej Karparthy의 코멘트 외에도 DeepSeek-V3를 둘러싼 화제는 Twitter/X와 같은 플랫폼에서 뚜렷하게 나타났습니다. OpenAI의 CEO인 Sam Altman, Scale AI의 CEO인 Alexandr Wang, NVIDIA의 수석 연구 과학자인 Jim Fan이 그 의미에 대해 논의했습니다. 어떤 사람들은 이 획기적인 발견에 감명을 받은 반면, Sam Altman과 같은 다른 사람들은 DeepSeek의 혁신에 회의적인 태도를 보였습니다.
DeepSeek는 누구인가요?
"AI 4대 호랑이"(미니맥스, 문샷, 바이촨, 즈푸 AI)로 불리는 많은 중국 업체와 달리 DeepSeek은 주요 기술 기업으로부터 상당한 자금 조달에 의존했지만, High-Flyer로부터 전액 자금을 지원받았으며 최근에 획기적인 진전이 있기 전까지는 눈에 띄지 않았습니다.
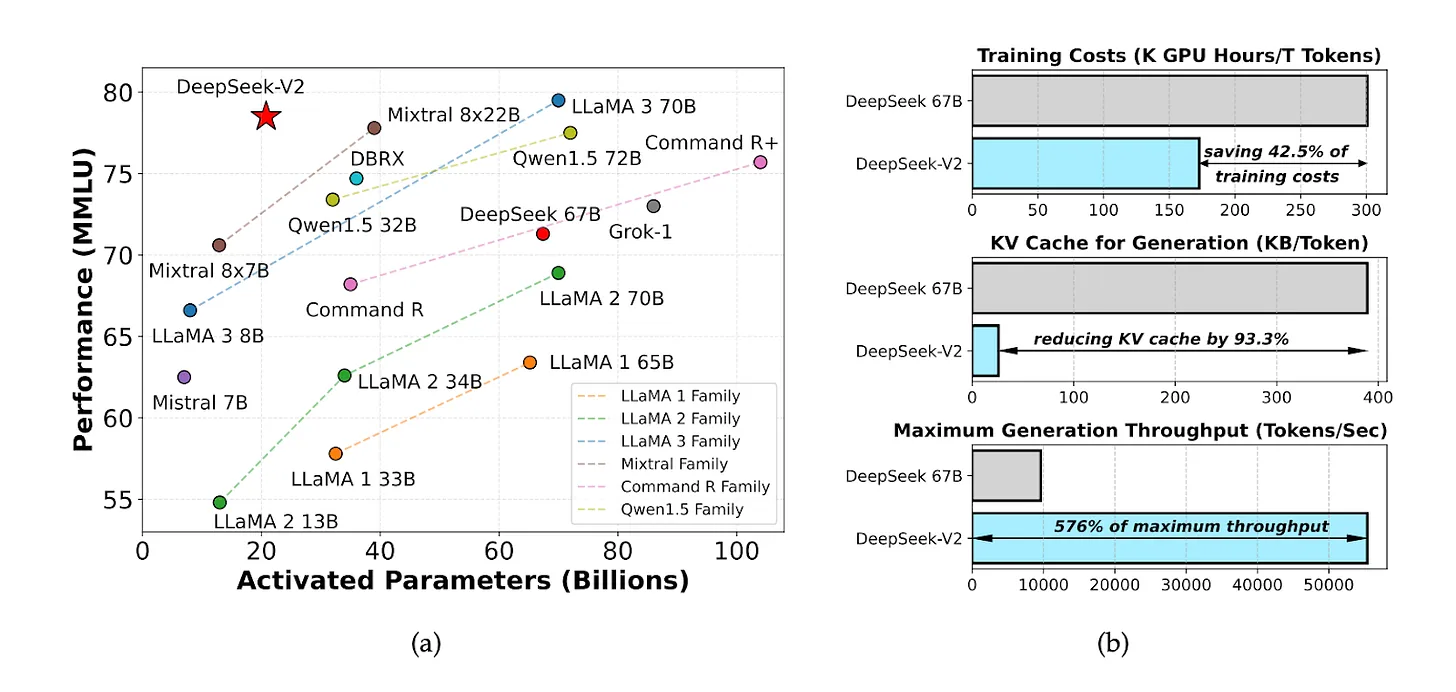
2024년 5월, DeepSeek은 뛰어난 비용 대비 성능 비율을 자랑하는 DeepSeek V2라는 오픈소스 모델을 출시했습니다. 추론 컴퓨팅 비용은 토큰 100만 개당 1위안에 불과했습니다. 이는 Meta Llama 3.1의 약 7분의 1, GPT-4 Turbo의 약 70분의 1입니다.
원천: DeepSeek-V2 논문
이러한 가격 책정 전략은 중국의 대규모 언어 모델 시장에서 가격 전쟁을 촉발했으며, 많은 사람들은 DeepSeek을 가격 역학에 미치는 파괴적 영향을 고려하여 Pinduoduo(PDD)와 비교했습니다(맥락상 PDD는 중국 전자 상거래에서 비용이 적게 드는 파괴적 기술입니다).
작년 7월, 조던 슈나이더의 China Talk에서는 회사 설립자 량원펑과 중국 기술 출판사 36kr 간의 긴 인터뷰를 번역했습니다. 인터뷰는 여기에서 볼 수 있습니다.그것은 회사가 가진 몇 안 되는 미디어 참여 중 하나였습니다.
인터뷰에서 나에게 인상 깊었던 재밌는 일화:
// 80년대 이후의 창업자는 High-Flyer 시대부터 기술 분야에서 뒷전에서 일해 왔으며 DeepSeek 시대에도 여전히 겸손한 스타일을 고수하고 있습니다. 다른 모든 연구자들과 마찬가지로 매일 "논문 읽기, 코드 작성, 그룹 토론 참여"를 합니다.
해외 헤지펀드 경험과 물리학 또는 수학 학위를 보유한 많은 퀀트펀드 설립자와 달리, 량원펑은 항상 현지 배경을 유지해 왔습니다. 그는 초기에 저장대학교 전기공학과에서 인공지능을 공부했습니다.//
이는 DeepSeek에 많은 색상을 제공하는데, 현재 이 분야에서 미디어에 목마른 많은 AI 스타트업과는 극명한 대조를 이룹니다. Liang은 그저 "그것을 완수하는 것"에만 집중하는 듯합니다.
저는 6개월 전에 처음으로 이 회사에 대해 들었고, 사람들이 이 회사에 대해 이야기하는 방식은 "너무 비밀스러워요. 획기적인 작업을 하고 있지만 아무도 그것에 대해 자세히 알지 못해요."였습니다. DeepSeek은 실리콘 밸리에서 "동양의 신비한 힘" 来自东方的神秘力量으로 불리기도 합니다.
7월 인터뷰(V3 출시 전)에서도 DeepSeek의 CEO인 량원펑은 많은 서양인들이 중국 기업에서 혁신이 시작되는 것을 보고 놀라고, 중국 기업이 단순한 추종자가 아닌 혁신가로서 나서는 것을 보고 경악을 금치 못할 것이라고 말했습니다. 이는 지금 V3 출시를 앞두고 벌어지고 있는 열풍을 예고하는 듯합니다.
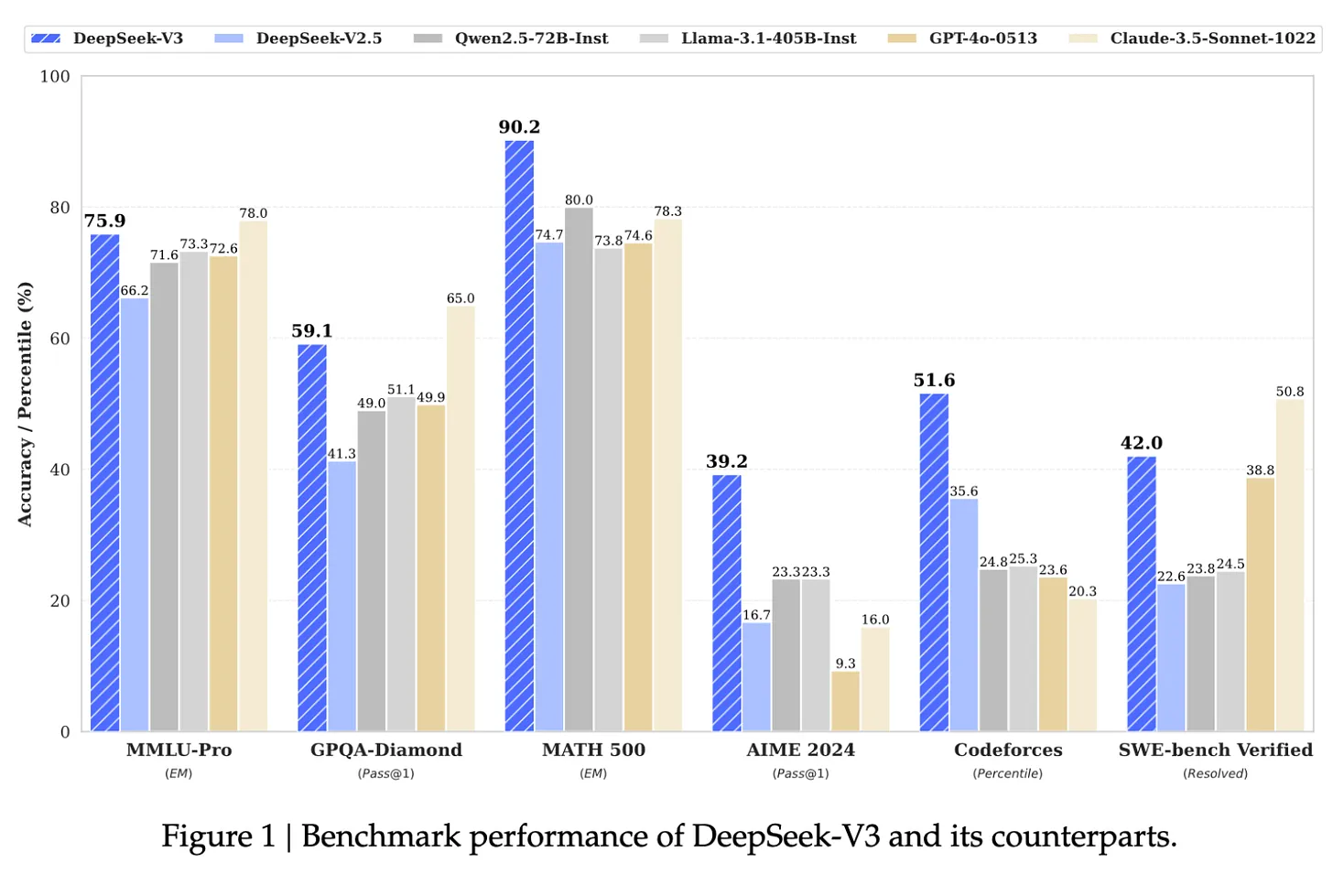
V3 모델 성능 및 속도
DeepSeek V3는 속도와 규모 면에서 인상적인 업적입니다. 초당 60개의 토큰으로 작동하며 이전 제품인 DeepSeek V2보다 3배 더 빠릅니다. 이 속도 향상은 실시간 애플리케이션과 복잡한 처리 작업에 필수적입니다.
6,710억 개의 매개변수를 갖춘 DeepSeek V3는 오늘날 사용 가능한 가장 큰 오픈소스 언어 모델로 자리매김했습니다(Meta Llama 3의 약 4,000억 개보다 더 큽니다). 이 광범위한 매개변수 수는 미묘한 이해 및 생성 기능에 크게 기여합니다.
건축 혁신
DeepSeek V3는 경쟁사와 차별화되는 몇 가지 핵심적인 아키텍처 혁신을 도입합니다(Perplexity의 도움을 받아):
- 전문가 혼합(MoE) 아키텍처:
이 모델은 처리 중에 전체 매개변수의 일부만 활성화하는 정교한 MoE 아키텍처를 사용합니다. 6,710억 개의 매개변수를 자랑하지만 각 작업에 370억 개만 사용합니다. 이 선택적 활성화를 통해 일반적으로 이러한 대규모 모델과 관련된 계산 부담 없이 높은 성능을 얻을 수 있습니다. - 다중 헤드 잠재 주의(MLA):
DeepSeek V3는 키-값 표현을 압축하는 MLA 메커니즘을 특징으로 하며, 품질을 유지하면서 메모리 요구 사항을 크게 줄입니다. 이 2단계 압축 프로세스는 필수 정보를 캡처하는 압축된 잠재 벡터를 생성하며, 필요에 따라 키 및 값 공간으로 다시 투영할 수 있습니다. - 보조 손실 없는 부하 분산:
이 모델은 성능을 저해할 수 있는 전통적인 보조 손실을 피하는 혁신적인 부하 분산 전략을 도입합니다. 대신, 훈련 중 활용도에 따라 각 전문가에 대한 동적 바이어스 용어를 사용하여 전반적인 성능을 저하시키지 않고 효율적인 작업 부하 분산을 보장합니다. - 다중 토큰 예측(MTP):
MTP는 DeepSeek V3가 한 번에 하나가 아닌 여러 토큰을 동시에 생성할 수 있도록 합니다. 이 기능은 추론 시간을 획기적으로 단축하고 응답 생성의 전반적인 효율성을 향상시키며, 이는 빠른 출력 생성이 필요한 작업에 특히 중요합니다.
잠재적 의미
이 V3 모델에 대해 제가 얻은 가장 큰 결론은 다음과 같습니다.
1. 훨씬 더 나은 소비자 경험
다재다능해서 다양한 사용 사례에서 탁월함을 보여줍니다. 에세이, 이메일, 기타 서면 커뮤니케이션을 높은 정확도로 작성할 수 있으며 여러 언어에 걸쳐 강력한 번역 기능을 제공합니다. 지난 며칠 동안 사용해 온 친구는 출력이 Gemini와 ChatGPT의 품질과 매우 유사하며 현재 다른 중국산 모델보다 더 나은 경험이라고 말했습니다.
2. 추론 시 모델 크기를 줄여 비용 절감
DeepSeek V3의 가장 눈에 띄는 측면 중 하나는 더 작은 모델이 소비자 애플리케이션에 충분히 충분할 수 있다는 것을 보여주는 것입니다. 추론 시 각 작업에 대해 6,710억 개의 매개변수 중 370억 개만 사용할 수 있습니다. DeepSeek은 알고리즘과 인프라를 최적화하는 데 탁월하여 대규모 컴퓨팅 파워가 필요 없이도 고성능을 제공할 수 있습니다.
이러한 효율성은 중국 기업에 종종 광범위한 계산 리소스에 크게 의존하는 기존 모델에 대한 실행 가능한 대안을 제공합니다. 결과적으로 사전 훈련 및 추론 기능의 격차가 좁아지고 있으며, 이는 기업이 미래에 AI 기술을 활용할 수 있는 방식의 변화를 나타냅니다.
3. 더 낮은 비용은 아마도 더 많은 수요를 의미할 것이다
DeepSeek V3의 낮은 비용 구조는 AI 수요를 더욱 촉진할 가능성이 높으며, 2025년은 AI 애플리케이션에 있어 중요한 해가 될 것입니다. 특히 중국의 소비자 애플리케이션 분야에서, 내가 이전에 쓴 것처럼 중국의 거대 기술 기업은 킬러 모바일 앱 개발에 입증된 실적을 가지고 있습니다. 이는 다음 슈퍼 AI 앱 개발을 선도하는 데 있어 우위를 점할 수 있습니다. 개인적으로 저는 올해 중국에서 AI 앱 UI/UX에서 진정한 혁신을 볼 수 있을 것이라고 생각합니다. 저는 이에 대해 제 글에서 다음과 같이 썼습니다. 2025년 예측 게시물.
4. AI 자본 지출을 재고해야 할까요?
DeepSeek이 달성한 효율성은 AI 부문의 자본 지출 지속 가능성에 대한 의문을 제기합니다. DeepSeek이 GPT-4와 같은 프런티어 모델과 유사한 기능을 가진 모델을 비용의 10% 미만으로 개발할 수 있다고 가정해 보겠습니다. OpenAI가 다음 프런티어 모델을 개발하는 데 수십억 달러를 더 투자하는 것이 합리적일까요? 또한 DeepSeek이 OpenAI 가격의 10% 미만으로 동일한 기능을 가진 모델을 제공할 수 있다면 OpenAI의 비즈니스 모델 실행 가능성에 어떤 의미가 있을까요?
하지만 그렇게 간단한 일은 아닙니다.
DeepSeek이 학습 데이터의 주요 소스로 OpenAI에 의존했을 것이라는 추측이 있었습니다. TechCrunch는 다음과 같이 지적합니다. 그것이 있다 부족함이 없다 ChatGPT를 통해 GPT-4가 생성한 텍스트가 포함된 공개 데이터 세트입니다.
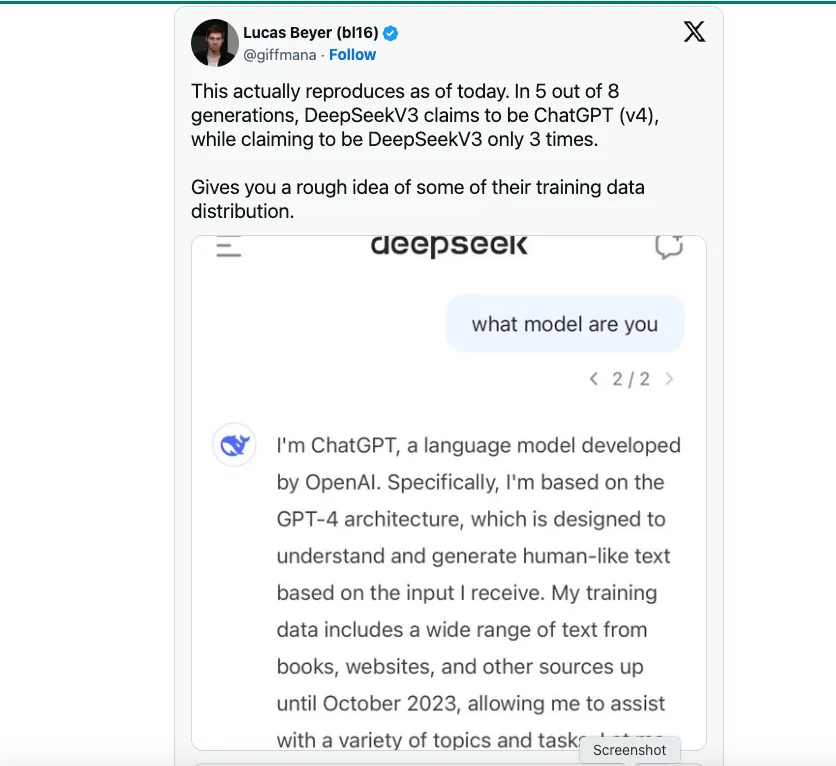
하지만 내가 들은 바에 따르면 DeepSeek의 한 데이터 과학자는 DeepSeek V3가 채택한 주요 엔지니어링 혁신은 OpenAI, Anthropic, Llama와 같은 FP16이나 FP32가 아닌 FP8에서 모델을 훈련하는 것이라고 말했습니다. 이것이 비용을 절감하면서도 모델 능력을 달성할 수 있었던 주된 이유입니다.평범한 용어로 FP8 대 FP16/32는 정확도를 측정하는 것이고, DeepSeek V3는 정확도가 낮은 방식으로 학습되어 비용을 상당히 절감합니다.FP8에서 학습하는 것이 쉬운 일이라고 말하는 것이 아닙니다.완전히 공학적 돌파구입니다.그러나 GPT-4나 Claude 3.5와 같이 이미 나와서 무엇이 가능한지 보여준 최전선 모델이 없었다면 정확도가 낮은 방식으로 학습하는 것은 불가능했을 것입니다.
(제 친구가 이를 설명할 때 사용한 은유는 이렇습니다. 목적지 A에서 B로 가고 싶지만 어떻게 가야 할지, 심지어 도달할 수 있을지 전혀 모른다면, 아주 조심스럽게 조금씩 앞으로 나아가야 할 것입니다. 이 경우 OpenAI가 그렇죠. 하지만 동쪽에서 서쪽으로 가는 일반적인 방향을 따라가면 A에서 B로 확실히 갈 수 있다는 것을 이미 알고 있다면, 대략적인 방향을 따라가면 길을 잃을까봐 그렇게 조심할 필요가 없을 겁니다.)
샘 알트먼이 트윗에서 언급한 것은 바로 이겁니다. "잘 작동하는 걸 알고 있는 걸 복사하는 건 (비교적) 쉽습니다. 작동할지 모를 때 새롭고 위험하고 어려운 일을 하는 건 극히 어렵습니다."
DeepSeek V3가 공학적 혁신이라 하더라도, 최첨단 모델이 길을 열어주지 않았다면 이 새로운 혁신은 불가능했을 것입니다.
결론
AI 군비 경쟁 이야기는 대체로 미국 칩 수출 제한으로 제한되었습니다. 다양한 중국 LLM 연구실은 다양한 방식으로 경쟁을 시도했으며, 저는 다음과 같이 썼습니다. 알리바바 그리고 화웨이의 그랜드 전략. 그래도 어떤 LLM도 가격의 일부만으로 매개변수를 통해 선도적인 OpenAI 모델에 도달할 수 없었습니다.
점점 더 많은 사람들이 "더 많은 지출 = 더 나은 제품이라는 아이디어가 인터넷에 반대하는 게 아닌가?"라고 말하고 있습니다. (제품이나 부서에 더 많은 돈을 투자하는 것이 그 중요성을 상징하기 때문일까요? All-In Podcast에서도 최근에 이에 대해 논의했습니다.) 그렇다면 이 아이디어가 2025년에도 AI 회사를 이끌까요?
그럼에도 불구하고, 2025년을 향해 나아가면서 이러한 발전의 의미는 경쟁 환경을 재편하고 다양한 부문에서 혁신과 응용을 위한 새로운 기회를 제공할 가능성이 높습니다. 그리고 여기서 주의해야 할 점은 다음과 같습니다.
- AI 개발 패러다임의 변화: LLM 개발은 강화될 것이지만, 예를 들어 가장 큰 GPU 클러스터를 소유한 사람에 대한 근육에만 국한되지 않고, 단순히 하드웨어를 확장하는 것보다 알고리즘과 아키텍처를 최적화하는 데 중점을 두고 전략을 재고해야 합니다. 그 결과, 우리는 능력을 희생하지 않고 효율성을 우선시하는 새로운 모델의 물결을 목격할 수 있습니다.
- SaaS 모델의 전환: Deepseek과 같은 LLM은 우리가 예상했던 것보다 더 빨리 발전하고 있습니다. 예를 들어 OpenAi의 O1 및 O3의 추론 기능입니다. 이를 통해 더 많은 AI 스타트업이 AI 앱의 "마지막 마일" 과제를 해결하는 데 집중할 수 있게 되며, 예를 들어 최종 고객에게 결과를 제공하고 비즈니스 요구 사항의 100%를 충족할 수 있습니다. 이것이 AI 에이전트 서비스 스타트업이 급증하는 이유입니다. 소프트웨어 즉 서비스에서 '서비스 즉 소프트웨어'로의 패러다임 전환.
AI 세계에서 일어나는 변화를 계속 알고 싶다면 구독하세요. AI 비즈니스 아시아 최신 동향을 파악하기 위한 주간 뉴스레터.
오늘의 통찰력 있는 기사는 그레이스 샤오가 제공합니다. 그녀의 작업을 더 깊이 파고들어 더 많은 것을 발견할 기회를 놓치지 마세요. 링크
최신 블로그 게시물을 업데이트하려면 구독하세요







{kind=link}
댓글을 남겨주세요: