
Deepseek-V3 により、China LLM は LLM Club のヘッドセットを獲得しました。
DeepSeek が最近リリースした V3 モデルは、その以前のバージョンである R1 がすでに西側諸国で注目を集め始めていたにもかかわらず、AI 業界に波紋を広げています。推定 $5.5 億から $8 億の運用資産を誇る中国有数の定量ファンドの 1 つである High-Flyer の支援を受け、DeepSeek は通常必要とされるトレーニング コストのほんの一部で、驚くべきモデル パフォーマンスを達成しました。
たとえば、テスラの元 AI 責任者で OpenAI の共同設立者の 1 人である Andrej Karpathy 氏によると、Meta の Llama 3-405B は 3,080 万 GPU 時間を使用したのに対し、DeepSeek-V3 は 280 万 GPU 時間しか使用せず、計算量が 11 分の 1 に抑えられた、より強力なモデルであるようです。これは、リソースの制約下での研究とエンジニアリングの非常に印象的な成果です。
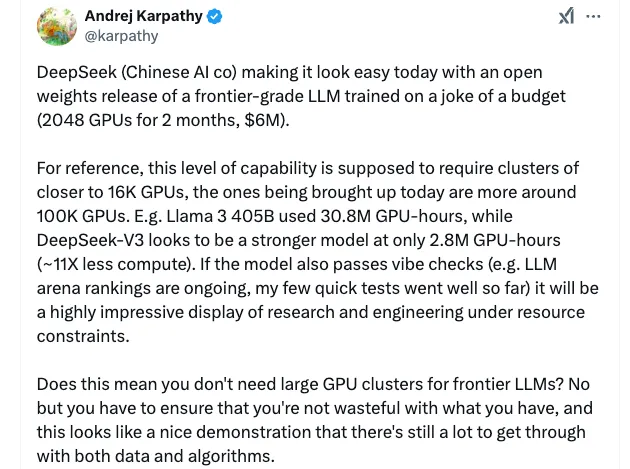
ソース: DeepSeek-V3 論文
Andrej Karparthy 氏のコメント以外にも、Twitter/X などのプラットフォームでは DeepSeek-V3 をめぐる話題が盛り上がっており、Sam Altman (OpenAI の CEO)、Alexandr Wang (Scale AI の CEO)、Jim Fan (NVIDIA のシニア リサーチ サイエンティスト) らがその影響について議論している。この画期的な成果に感銘を受けた人もいるようだが、Sam Altman 氏のように DeepSeek の革新性に懐疑的な意見を表明する人もいた。
DeepSeek とは誰ですか?
「AI四虎」(Minimax、Moonshot、Baichuan、Zhipu AI)と呼ばれる中国の同業他社の多くとは異なり、DeepSeekはHigh-Flyerから全額出資を受けており、最近の躍進までは目立たない存在だった。
2024年5月、DeepSeekは、優れたコストパフォーマンスを誇るオープンソースモデル「DeepSeek V2」を発表しました。推論コンピューティングコストは100万トークンあたりわずか1元で、Meta Llama 3.1の約7分の1、GPT-4 Turboの約70分の1です。
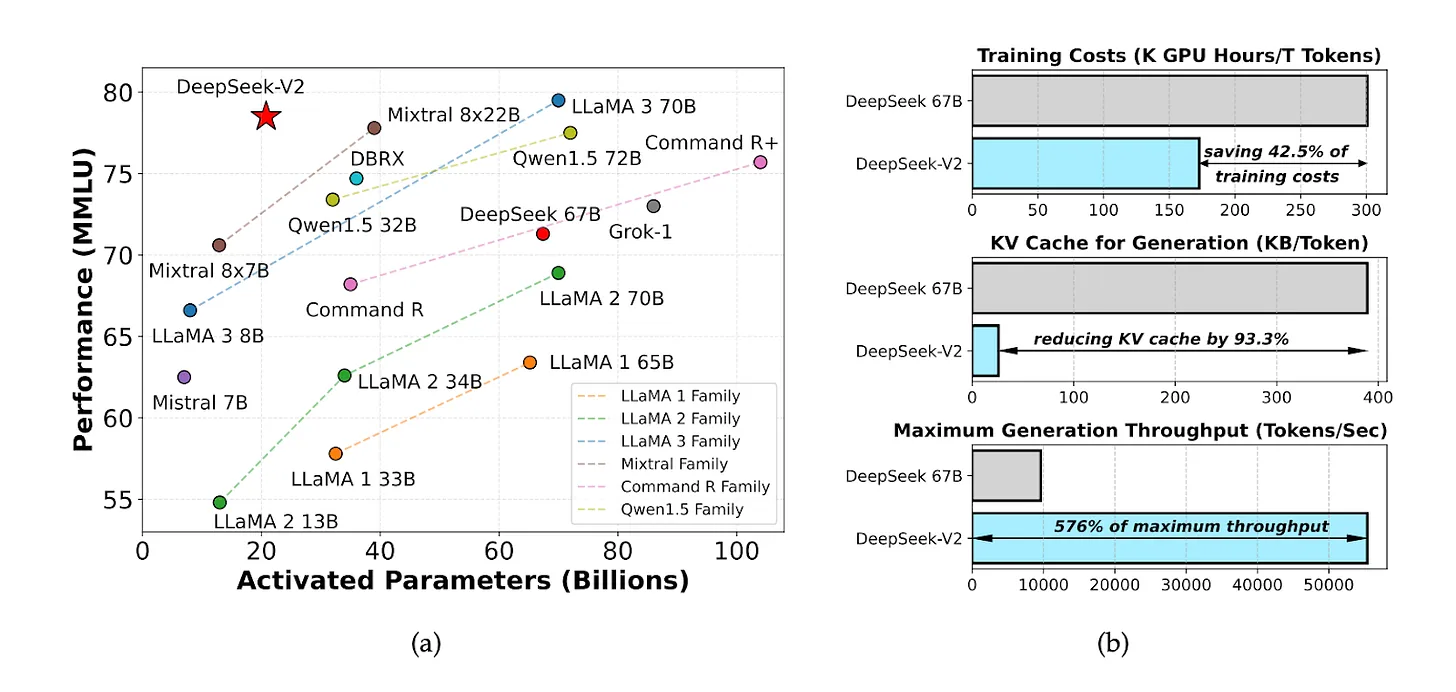
ソース: DeepSeek-V2 論文
この価格戦略は中国の大規模な言語モデル市場で価格戦争を引き起こし、価格動向に破壊的な影響を与えた DeepSeek を Pinduoduo (PDD) にすぐに例える人が多くいました (ちなみに、PDD は中国の電子商取引における低コストの破壊者です)。
昨年7月、ジョーダン・シュナイダーのChina Talkは、同社の創設者である梁文鋒氏と中国のテクノロジー出版物36krとの長いインタビューを翻訳した。 インタビューはここからご覧いただけますこれは同社が行った数少ないメディア出演のうちの1つでした。
インタビューの中で私が印象に残った面白い逸話は次の通りです。
// High-Flyer 時代からテクノロジーの舞台裏で働いてきた 80 年代以降の創設者は、DeepSeek 時代でも控えめなスタイルを続けています。つまり、「論文を読み、コードを書き、グループ ディスカッションに参加する」という、他のすべての研究者と同じように毎日やっていることです。
海外のヘッジファンドでの経験があり、物理学や数学の学位を持つ多くのクオンツファンドの創設者とは異なり、梁文鋒氏は常に地元のバックグラウンドを維持してきた。若い頃は浙江大学の電気工学部で人工知能を学んだ。//
これは DeepSeek にとって大きな意味を持ち、現在この分野でメディアに飢えている多くの AI スタートアップとは対照的だ。Liang 氏は「やり遂げる」ことだけに集中しているようだ。
私がこの会社について初めて知ったのは、約 6 か月前のことですが、当時の人々の話では、「非常に秘密主義で、画期的な仕事をしているが、それ以上のことは誰も知らない」というものでした。DeepSeek は、シリコンバレーで「東からの謎の勢力」とさえ呼ばれているそうです。
7月のインタビュー(V3のリリース前)でも、DeepSeekのCEOであるLiang Wenfeng氏は、多くの西洋人は中国企業からイノベーションが生まれることにただただ驚き、中国企業が単なる追随者ではなくイノベーターとして躍進していることに愕然とするだろう、と語っていた。 これは、現在 V3 リリースをめぐって起こっている熱狂の前兆です。
V3モデルのパフォーマンスと速度
DeepSeek V3 は、速度とスケールの両面で驚異的な成果をあげています。1 秒あたり 60 トークンで動作し、前身の DeepSeek V2 より 3 倍高速です。この速度向上は、リアルタイム アプリケーションや複雑な処理タスクにとって非常に重要です。
6,710 億のパラメータを持つ DeepSeek V3 は、現在利用可能な最大のオープンソース言語モデルです (約 4,000 億の Meta Llama 3 よりもさらに大きい)。この膨大なパラメータ数は、微妙なニュアンスの理解と生成機能に大きく貢献しています。
建築の革新
DeepSeek V3 では、競合他社との差別化を図るいくつかの重要なアーキテクチャ上の革新が導入されています (Perplexity の協力により)。
- 専門家混合(MoE)アーキテクチャ:
このモデルは、処理中に全パラメータの一部のみをアクティブにする高度な MoE アーキテクチャを採用しています。6,710 億のパラメータを誇りますが、各タスクで使用されるのは 370 億のみです。この選択的なアクティブ化により、このような大規模なモデルに通常伴う計算負荷をかけずに、高いパフォーマンスを実現できます。 - マルチヘッド潜在的注意 (MLA):
DeepSeek V3 は、キーと値の表現を圧縮する MLA メカニズムを備えており、品質を維持しながらメモリ要件を大幅に削減します。この 2 段階の圧縮プロセスにより、重要な情報をキャプチャする圧縮された潜在ベクトルが生成され、必要に応じてキーと値の空間に投影し直すことができます。 - 補助損失のない負荷分散:
このモデルは、パフォーマンスを低下させる可能性のある従来の補助損失を回避する革新的な負荷分散戦略を導入しています。代わりに、トレーニング中の使用率に基づいて各エキスパートに動的なバイアス項を採用し、全体的なパフォーマンスを損なうことなく効率的な作業負荷分散を保証します。 - マルチトークン予測 (MTP):
MTP により、DeepSeek V3 はトークンを 1 つずつではなく、同時に複数生成できるようになります。この機能により推論時間が大幅に短縮され、応答生成の全体的な効率が向上します。これは、迅速な出力生成を必要とするタスクにとって特に重要です。
潜在的な影響
この V3 モデルに関して私が得た最大のポイントは次のとおりです。
1. 消費者体験が大幅に向上
その汎用性により、さまざまな使用ケースで優れた性能を発揮します。エッセイ、メール、その他の書面によるコミュニケーションを高精度で作成でき、複数の言語にまたがる強力な翻訳機能も備えています。ここ数日間使用している友人によると、出力の品質は Gemini や ChatGPT と非常に似ており、現時点では他の中国製モデルよりも優れているとのことです。
2. 推論時のモデルサイズを縮小してコストを削減
DeepSeek V3 の最も印象的な側面の 1 つは、より小さなモデルでも消費者向けアプリケーションに十分対応できることを実証したことです。推論時に各タスクの 6,710 億個のパラメータのうち 370 億個のみを処理できます。DeepSeek はアルゴリズムとインフラストラクチャの最適化に優れており、膨大な計算能力を必要とせずに高いパフォーマンスを実現できます。
この効率性により、中国企業は、大規模な計算リソースに大きく依存する従来のモデルに代わる現実的な選択肢を手にすることになる。その結果、事前トレーニングと推論機能のギャップは縮まりつつあり、将来的に企業が AI テクノロジーを活用する方法に変化が起きる兆しとなるかもしれない。
3. コストが下がると需要が増える可能性がある
DeepSeek V3の低コスト構造はAI需要をさらに押し上げる可能性があり、2025年はAIアプリケーションにとって重要な年となるでしょう。特に中国の消費者向けアプリケーション分野では、 以前にも書いたように、中国の大手テクノロジー企業はキラーモバイルアプリの開発で実績がある。 これは、次世代のスーパーAIアプリの開発をリードする上での優位性となるかもしれません。個人的には、今年は中国からAIアプリのUI/UXの真の革新が見られると思います。これについては、私のブログでも書きました。 2025年の予測投稿。
4. AI 設備投資を再考しますか?
DeepSeek が達成した効率性は、AI 分野における設備投資の持続可能性について疑問を投げかけています。DeepSeek が GPT-4 のような最先端のモデルと同様の機能を持つモデルを 10% 未満のコストで開発できるとします。OpenAI が次の最先端のモデルの開発にさらに数百億ドルを投入するのは理にかなっていますか? また、DeepSeek が同じ機能を持つモデルを OpenAI の 10% 未満の価格で提供できる場合、これは OpenAI のビジネス モデルの実現可能性にとって何を意味するのでしょうか?
しかし、それはそれほど単純ではありません。
DeepSeek がトレーニング データの主なソースとして OpenAI に依存していた可能性があるという憶測が流れている。 TechCrunchは指摘する ある 不足なし ChatGPT 経由で GPT-4 によって生成されたテキストを含む公開データセット。
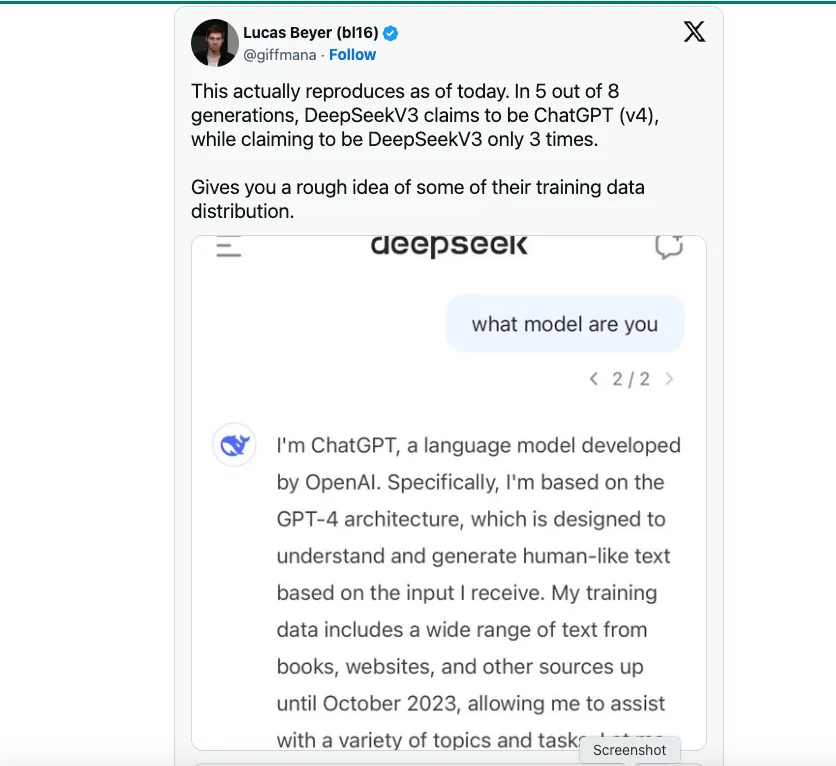
しかし、私が聞いたところによると、DeepSeek のデータ サイエンティストは、DeepSeek V3 が採用した重要なエンジニアリング イノベーションは、OpenAI、Anthropic、Llama のように FP16 や FP32 ではなく FP8 でモデルをトレーニングすることだと言っていました。 これが、コストを削減しながらもモデルの能力を達成できた主な理由です。簡単に言えば、FP8 と FP16/32 は精度の尺度であり、DeepSeek V3 は精度を低くしてトレーニングされるため、コストが大幅に削減されます。FP8 でのトレーニングが簡単だと言っているのではありません。これは完全にエンジニアリングのブレークスルーです。ただし、GPT-4 や Claude 3.5 などの最先端のモデルがすでに登場して可能性を示していなければ、精度を低くしてトレーニングすることは不可能でした。
(友人が私にこれを説明するために使った比喩は、次のようなものです。目的地 A から B に行きたいが、そこにどうやって行くのか、そもそも到達できるのかどうかがわからない場合、あなたは非常に慎重に少しずつ前進するでしょう。つまり、この場合は OpenAI です。しかし、東から西への大まかな方向に従って A から B に確実に到達できることがすでにわかっている場合は、大まかな方向に従うだけで、軌道から外れる心配をする必要はありません。)
サム・アルトマンがツイートで言及していたのは、まさにこれです。「うまくいくとわかっているものをコピーするのは(比較的)簡単です。うまくいくかどうかわからないときに、何か新しい、リスクのある、難しいことをするのは非常に困難です。」
DeepSeek V3 はエンジニアリング上の画期的な進歩ですが、道を切り開く最先端のモデルがなければ、この新たな進歩は実現できなかったでしょう。
結論
AI軍拡競争の物語は、米国のチップ輸出規制によってほぼ制限されている。中国の様々な法学修士研究室が様々な方法で競争しようとしており、私は アリババ そして ファーウェイの 壮大な戦略。それでも、わずかな費用で、パラメータ全体にわたって主要な OpenAI モデルにこれほど明白に到達できた LLM は実際にはありません。
「支出が増える=製品が良くなるという考え方はインターネットに反するのではないか」という声がますます高まっています(製品や部門に投入されるお金が増えることは、その重要性を象徴するからでしょうか? All-In Podcast でも最近この点について議論されました)。では、この考えは 2025 年も AI 企業を導くのでしょうか?
それでも、2025年に向けて、これらの進歩の影響により競争環境が再編され、さまざまな分野でのイノベーションと応用の新たな機会がもたらされる可能性が高い。ここで注目すべき点を挙げる。
- AI開発パラダイムの転換: LLM の開発は強化されますが、筋肉だけではありません。たとえば、誰が最大の GPU クラスターを所有しているかなど、戦略を再考し、ハードウェアをスケールアップするだけでなく、アルゴリズムとアーキテクチャを最適化することに焦点を当てます。その結果、機能を犠牲にすることなく効率を優先する新しいモデルの波が現れるかもしれません。
- SaaSモデルの転換: DeepseekなどのLLMは、OpenAiのO1とO3の推論機能など、予想よりも速く進歩しています。これにより、より多くのAIスタートアップが、AIアプリの「ラストマイル」の課題の解決に注力するようになります。たとえば、エンドユーザーに結果を提供したり、100%のビジネス要件を満たしたりすることなどです。これが、AIエージェントサービスのスタートアップが急増している理由です。 サービスとしてのソフトウェアからソフトウェアとしてのサービスへのパラダイムシフト.
AIの世界で起こっている変化を常に把握したい方は、 AIビジネスアジア 時代の先を行くための週刊ニュースレター。
本日の洞察に満ちた記事は、Grace Shao がお届けします。彼女の作品を深く掘り下げて、さらに詳しく知る機会をお見逃しなく。 リンク
最新のブログ投稿の更新情報を受け取るには購読してください








{kind=link}
コメントを残す: