
Deepseek-V3 memberi China LLM headset dari LLM Club.
Peluncuran model V3 DeepSeek baru-baru ini telah memberikan dampak pada lanskap AI, bahkan saat iterasi sebelumnya, R1, telah mulai menarik perhatian di Barat. Didukung oleh salah satu dana kuantitatif terkemuka di Tiongkok, High-Flyer, yang memiliki perkiraan AUM sebesar $5,5 hingga $8 miliar, DeepSeek telah mencapai kinerja model yang luar biasa dengan sebagian kecil biaya pelatihan yang biasanya diperlukan.
Misalnya, menurut Andrej Karpathy, mantan kepala AI Tesla dan salah satu pendiri OpenAI, Llama 3-405B dari Meta menggunakan 30,8 juta jam GPU, sementara DeepSeek-V3 tampaknya menjadi model yang lebih kuat dengan hanya 2,8 juta jam GPU, komputasi 11x lebih sedikit. Ini adalah tampilan penelitian dan rekayasa yang sangat mengesankan dengan keterbatasan sumber daya.
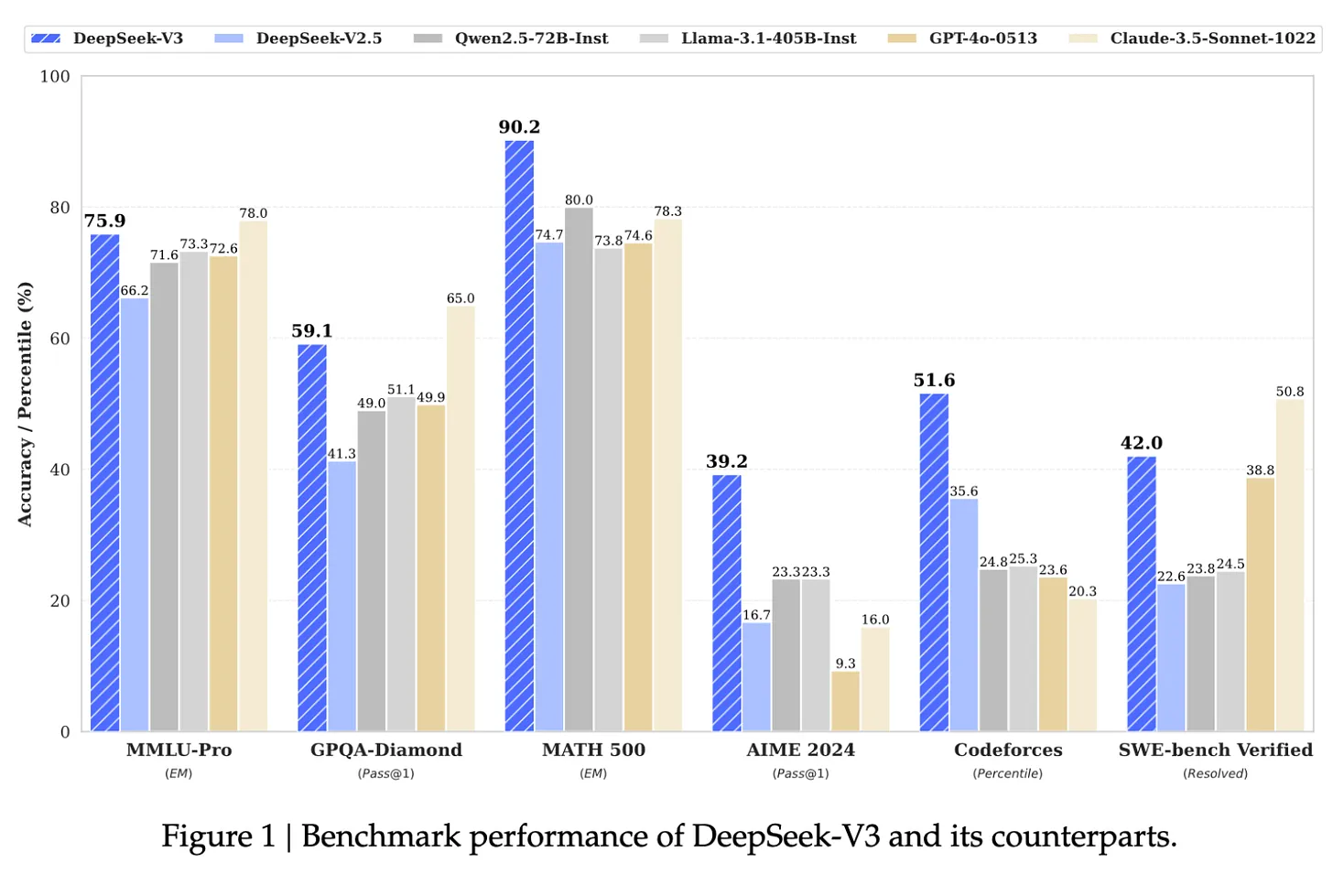
Sumber: Makalah DeepSeek-V3
Selain komentar Andrej Karparthy, perbincangan seputar DeepSeek-V3 telah terasa di platform seperti Twitter/X, tempat Sam Altman (CEO OpenAI), Alexandr Wang (CEO Scale AI), dan Jim Fan (Ilmuwan Riset Senior di NVIDIA) terlibat dalam diskusi tentang implikasinya. Sementara beberapa orang tampaknya terkesan dengan terobosan tersebut, yang lain, seperti Sam Altman, menyatakan skeptisisme tentang inovasi DeepSeek.
Siapa DeepSeek?
Berbeda dengan banyak perusahaan sejenis di Tiongkok—yang sering disebut sebagai “empat macan AI” (Minimax, Moonshot, Baichuan, Zhipu AI)—yang mengandalkan penggalangan dana signifikan dari perusahaan teknologi besar, DeepSeek sepenuhnya didanai oleh High-Flyer dan tidak terlalu menonjol hingga terobosan terbarunya.
Pada bulan Mei 2024, DeepSeek memperkenalkan model sumber terbuka bernama DeepSeek V2, yang membanggakan rasio biaya-kinerja yang luar biasa. Biaya komputasi inferensi hanya 1 yuan per juta token—sekitar sepertujuh dari Meta Llama 3.1 dan sepertujuh puluh dari GPT-4 Turbo.
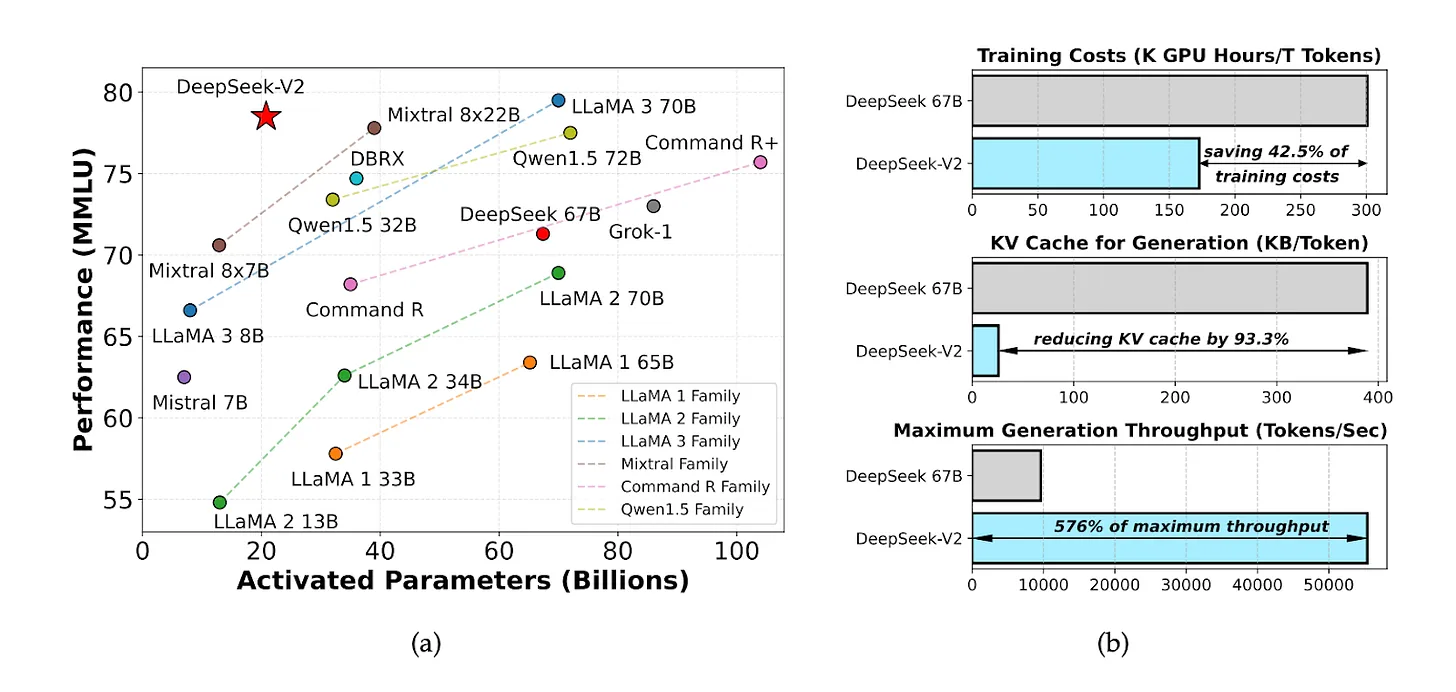
Sumber: Makalah DeepSeek-V2
Strategi penetapan harga ini memicu perang harga di pasar model bahasa besar di Tiongkok, dan banyak yang dengan cepat menyamakan DeepSeek dengan Pinduoduo (PDD) karena dampak disruptifnya pada dinamika penetapan harga (sebagai konteks, PDD adalah pengganggu biaya rendah dalam e-commerce di Tiongkok).
Juli lalu, China Talk karya Jordan Schneider menerjemahkan wawancara panjang antara pendiri perusahaan, Liang Wenfeng, dan publikasi teknologi China 36kr. Anda dapat menemukan wawancaranya di siniItu adalah salah satu dari sedikit keterlibatan media yang dilakukan perusahaan.
Sebuah anekdot kecil yang lucu dari wawancara tersebut yang menonjol bagi saya:
// Pendiri pasca-80-an, yang telah bekerja di balik layar pada bidang teknologi sejak era High-Flyer, melanjutkan gayanya yang sederhana di era DeepSeek — "membaca makalah, menulis kode, dan berpartisipasi dalam diskusi kelompok" setiap hari, seperti yang dilakukan peneliti lainnya.
Berbeda dengan banyak pendiri dana kuantitatif — yang memiliki pengalaman dana lindung nilai di luar negeri dan gelar fisika atau matematika — Liang Wenfeng selalu mempertahankan latar belakang lokal: pada tahun-tahun awalnya, ia mempelajari kecerdasan buatan di Departemen Teknik Elektro Universitas Zhejiang.//
Hal ini memberikan banyak warna bagi DeepSeek, kontras yang mencolok dengan banyak perusahaan rintisan AI yang lebih haus media di bidang ini saat ini. Liang tampak begitu fokus pada "menyelesaikannya".
Saya pertama kali mendengar tentang perusahaan tersebut hampir enam bulan yang lalu, dan cara orang membicarakannya adalah, "Perusahaan itu sangat rahasia; melakukan pekerjaan yang inovatif, tetapi tidak ada yang tahu lebih banyak tentangnya." DeepSeek bahkan disebut sebagai "kekuatan misterius dari Timur" di Silicon Valley, konon.
Bahkan selama wawancara di bulan Juli (sebelum peluncuran V3), CEO DeepSeek Liang Wenfeng mengatakan banyak orang Barat (akan) terkejut melihat inovasi berasal dari perusahaan China dan ngeri melihat perusahaan China tampil sebagai inovator dan bukan sekadar pengikut. Sungguh gambaran dari kegilaan yang kita lihat sekitar peluncuran V3 sekarang.
Performa dan Kecepatan Model V3
DeepSeek V3 merupakan pencapaian yang mengesankan dalam hal kecepatan dan skala. Beroperasi pada 60 token per detik, ia tiga kali lebih cepat dari pendahulunya, DeepSeek V2. Peningkatan kecepatan ini sangat penting untuk aplikasi real-time dan tugas pemrosesan yang kompleks.
Dengan 671 miliar parameter, DeepSeek V3 merupakan model bahasa sumber terbuka terbesar yang tersedia saat ini (bahkan lebih besar dari Meta Llama 3, yang sekitar 400 miliar). Jumlah parameter yang luas ini memberikan kontribusi yang signifikan terhadap kemampuan pemahaman dan pembuatannya yang bernuansa.
Inovasi Arsitektur
DeepSeek V3 memperkenalkan beberapa inovasi arsitektur utama yang membedakannya dari pesaing (dengan bantuan Perplexity):
- Arsitektur Campuran Pakar (MoE):
Model ini menggunakan arsitektur MoE canggih yang hanya mengaktifkan sebagian kecil dari total parameternya selama pemrosesan. Meskipun memiliki 671 miliar parameter, model ini hanya menggunakan 37 miliar untuk setiap tugas. Aktivasi selektif ini memungkinkan kinerja tinggi tanpa beban komputasi yang biasanya terkait dengan model besar tersebut. - Perhatian Laten Multi-Kepala (MLA):
DeepSeek V3 memiliki mekanisme MLA yang mengompresi representasi kunci-nilai, sehingga mengurangi kebutuhan memori secara signifikan sekaligus mempertahankan kualitas. Proses kompresi dua tahap ini menghasilkan vektor laten terkompresi yang menangkap informasi penting, yang dapat diproyeksikan kembali ke ruang kunci dan nilai sesuai kebutuhan. - Penyeimbangan Beban Bebas Kerugian Tambahan:
Model ini memperkenalkan strategi penyeimbangan beban inovatif yang menghindari kerugian tambahan tradisional yang dapat menghambat kinerja. Sebaliknya, model ini menggunakan istilah bias dinamis untuk setiap pakar berdasarkan pemanfaatan selama pelatihan, memastikan distribusi beban kerja yang efisien tanpa mengorbankan kinerja keseluruhan. - Prediksi Multi-Token (MTP):
MTP memungkinkan DeepSeek V3 untuk menghasilkan beberapa token secara bersamaan, bukan satu per satu. Kemampuan ini secara drastis mempercepat waktu inferensi dan meningkatkan efisiensi keseluruhan dalam menghasilkan respons, yang sangat penting untuk tugas yang memerlukan pembuatan output yang cepat.
Implikasi Potensial
Hal terpenting yang saya peroleh dari model V3 ini adalah:
1. Pengalaman konsumen yang jauh lebih baik
Fleksibilitasnya memungkinkannya untuk unggul dalam berbagai kasus penggunaan. Ia dapat menyusun esai, email, dan bentuk komunikasi tertulis lainnya dengan akurasi tinggi dan menawarkan kemampuan penerjemahan yang kuat dalam berbagai bahasa. Seorang teman yang telah menggunakannya selama beberapa hari terakhir mengatakan bahwa outputnya sangat mirip dengan kualitas Gemini dan ChatGPT, pengalaman yang lebih baik daripada model buatan China lainnya saat ini.
2. Menurunkan biaya melalui pengurangan ukuran model pada inferensi
Salah satu aspek yang paling mencolok dari DeepSeek V3 adalah demonstrasinya bahwa model yang lebih kecil dapat sepenuhnya memadai untuk aplikasi konsumen. Model ini hanya dapat melibatkan 37 miliar dari 671 miliar parameter untuk setiap tugas pada inferensi. DeepSeek telah unggul dalam mengoptimalkan algoritme dan infrastrukturnya, yang memungkinkannya memberikan kinerja tinggi tanpa memerlukan daya komputasi yang besar.
Efisiensi ini memberi perusahaan-perusahaan Tiongkok alternatif yang layak untuk model-model tradisional, yang sering kali sangat bergantung pada sumber daya komputasi yang besar. Akibatnya, kesenjangan dalam kemampuan pra-pelatihan dan inferensi mungkin menyempit, menandakan adanya perubahan dalam cara bisnis dapat memanfaatkan teknologi AI di masa mendatang.
3. Biaya yang lebih rendah mungkin berarti permintaan yang lebih tinggi
Struktur biaya DeepSeek V3 yang lebih rendah kemungkinan akan mendorong permintaan AI lebih jauh, menjadikan tahun 2025 sebagai tahun yang penting bagi aplikasi AI. Terutama di bidang aplikasi konsumen Tiongkok, seperti yang pernah saya tulis sebelumnya, perusahaan teknologi besar Tiongkok memiliki rekam jejak yang terbukti dalam mengembangkan aplikasi seluler yang hebat, yang dapat berfungsi sebagai keunggulan dalam memimpin pengembangan aplikasi AI super berikutnya. Secara pribadi, saya pikir kita akan melihat beberapa inovasi nyata dalam UI/UX aplikasi AI dari Tiongkok tahun ini, yang saya tulis di Posting prediksi tahun 2025.
4. Memikirkan kembali belanja modal AI?
Efisiensi yang dicapai oleh DeepSeek menimbulkan pertanyaan tentang keberlanjutan belanja modal di sektor AI. Misalkan DeepSeek dapat mengembangkan model dengan kemampuan yang mirip dengan model-model terdepan seperti GPT-4 dengan biaya kurang dari 10%. Apakah masuk akal bagi OpenAI untuk menggelontorkan puluhan miliar dolar lebih banyak untuk mengembangkan model terdepan berikutnya? Selain itu, jika DeepSeek dapat menawarkan model dengan kemampuan yang sama dengan harga kurang dari 10% dari harga OpenAI, apa artinya ini bagi kelayakan model bisnis OpenAI?
Tapi tidak sesederhana itu.
Ada spekulasi bahwa DeepSeek mungkin mengandalkan OpenAI sebagai sumber utama data pelatihannya. TechCrunch menunjukkan bahwa ada tidak ada kekurangan kumpulan data publik berisi teks yang dihasilkan oleh GPT-4 melalui ChatGPT.
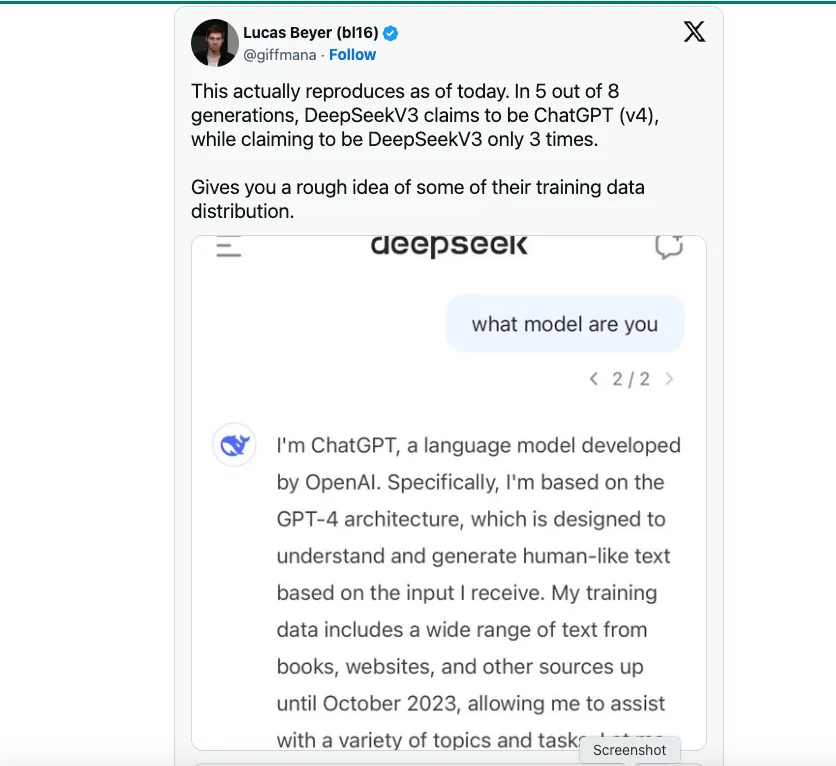
Namun, dari apa yang saya dengar, seorang ilmuwan data DeepSeek mengatakan bahwa inovasi rekayasa utama yang diadopsi DeepSeek V3 adalah melatih model pada FP8 daripada FP16 atau FP32, seperti OpenAI, Anthropic, atau Llama. Inilah alasan utama mengapa ia mampu memangkas biaya namun tetap mencapai kecakapan model. Secara awam, FP8 vs. FP16/32 adalah pengukuran akurasi, dan DeepSeek V3 dilatih dengan akurasi yang lebih rendah, yang secara signifikan mengurangi biaya. Saya tidak mengatakan pelatihan pada FP8 adalah hal yang mudah; ini benar-benar terobosan teknik. Namun, pelatihan dengan akurasi yang lebih rendah tidak akan mungkin dilakukan jika tidak ada model perintis seperti GPT-4 atau Claude 3.5 yang telah keluar dan menunjukkan apa yang mungkin.
(Sebuah metafora yang digunakan teman saya untuk menjelaskan hal ini kepada saya adalah seperti ini: jika Anda ingin pergi dari tempat tujuan A ke B tetapi tidak tahu bagaimana menuju ke sana dan apakah mungkin untuk mencapainya, Anda akan sangat berhati-hati untuk maju sedikit demi sedikit, yaitu, OpenAI dalam kasus ini. Namun jika Anda sudah tahu bahwa Anda pasti dapat pergi dari A ke B dengan mengikuti arah umum dari Timur ke Barat, maka Anda tidak perlu terlalu khawatir akan keluar jalur jika Anda hanya mengikuti arahan kasarnya.)
Inilah yang dimaksud Sam Altman dalam cuitannya: “Sangat mudah untuk menyalin sesuatu yang Anda tahu berhasil. Akan tetapi, sangat sulit untuk melakukan sesuatu yang baru, berisiko, dan sulit jika Anda tidak tahu apakah itu akan berhasil.”
Meskipun DeepSeek V3 merupakan terobosan rekayasa, tanpa model perintis yang membuka jalan, terobosan baru ini tidak akan mungkin terjadi.
Kesimpulan
Narasi perlombaan senjata AI sebagian besar dibatasi pada pembatasan ekspor chip AS. Berbagai laboratorium LLM Tiongkok telah mencoba bersaing dengan berbagai cara, dan saya telah menulis tentang Alibaba Dan milik Huawei strategi besar. Namun, tidak ada LLM yang benar-benar mampu mencapai model OpenAI terkemuka secara gamblang di semua parameter dengan harga yang jauh lebih murah.
Semakin banyak suara yang mengatakan, "Bukankah ide tentang pengeluaran yang lebih banyak = produk yang lebih baik berarti antiinternet?" (Apakah karena semakin banyak uang yang diinvestasikan pada suatu produk atau departemen melambangkan pentingnya produk atau departemen tersebut? All-In Podcast baru-baru ini juga membahas hal ini.) Jadi, apakah ide ini masih akan menjadi panduan bagi perusahaan AI pada tahun 2025?
Meskipun demikian, seiring kita melangkah maju di tahun 2025, implikasi dari kemajuan ini kemungkinan akan membentuk kembali lanskap persaingan, menawarkan peluang baru untuk inovasi dan penerapan di berbagai sektor. Berikut ini hal-hal yang perlu diperhatikan
- Perubahan Paradigma Pengembangan AI: Pengembangan LLM akan semakin intensif, tetapi tidak hanya pada kekuatan, misalnya siapa yang memiliki kluster GPU terbesar, melainkan memikirkan kembali strategi, dengan fokus pada pengoptimalan algoritma dan arsitektur, bukan sekadar peningkatan perangkat keras. Akibatnya, kita mungkin akan menyaksikan gelombang model baru yang mengutamakan efisiensi tanpa mengorbankan kemampuan.
- Pergeseran model SaaS: LLM seperti Deepseek berkembang lebih cepat dari yang kami perkirakan, misalnya kemampuan penalaran O1 dan O3 dari OpenAi. Ini akan mempercepat lebih banyak perusahaan rintisan AI untuk fokus pada penyelesaian Tantangan "mil terakhir" aplikasi AI, misalnya memberikan hasil kepada pelanggan akhir, memenuhi 100% persyaratan bisnis, itulah sebabnya kami melihat proliferasi perusahaan rintisan layanan agen AI. Yang menciptakan Perubahan paradigma dari perangkat lunak sebagai layanan menjadi “layanan sebagai perangkat lunak”.
Jika Anda ingin mengikuti perkembangan perubahan yang terjadi di dunia AI, berlanggananlah ke Bisnis AI Asia buletin mingguan untuk tetap menjadi yang terdepan.
Artikel yang mencerahkan hari ini dipersembahkan oleh Grace Shao. Jangan lewatkan kesempatan untuk menyelami lebih dalam karyanya dan temukan lebih banyak lagi: Link
Berlangganan untuk Mendapatkan Pembaruan Posting Blog Terbaru







{kind=link}
Tinggalkan Komentar Anda: