
Deepseek-V3 permet à China LLM de remporter un prix du LLM Club.
Le lancement récent du modèle V3 de DeepSeek a fait des vagues dans le paysage de l'IA, même si sa version précédente, R1, avait déjà commencé à attirer l'attention en Occident. Soutenu par l'un des principaux fonds quantitatifs chinois, High-Flyer, qui revendique un encours estimé entre 145,5 et 148 milliards de dollars, DeepSeek a obtenu des performances de modèle remarquables avec une fraction du coût de formation généralement requis.
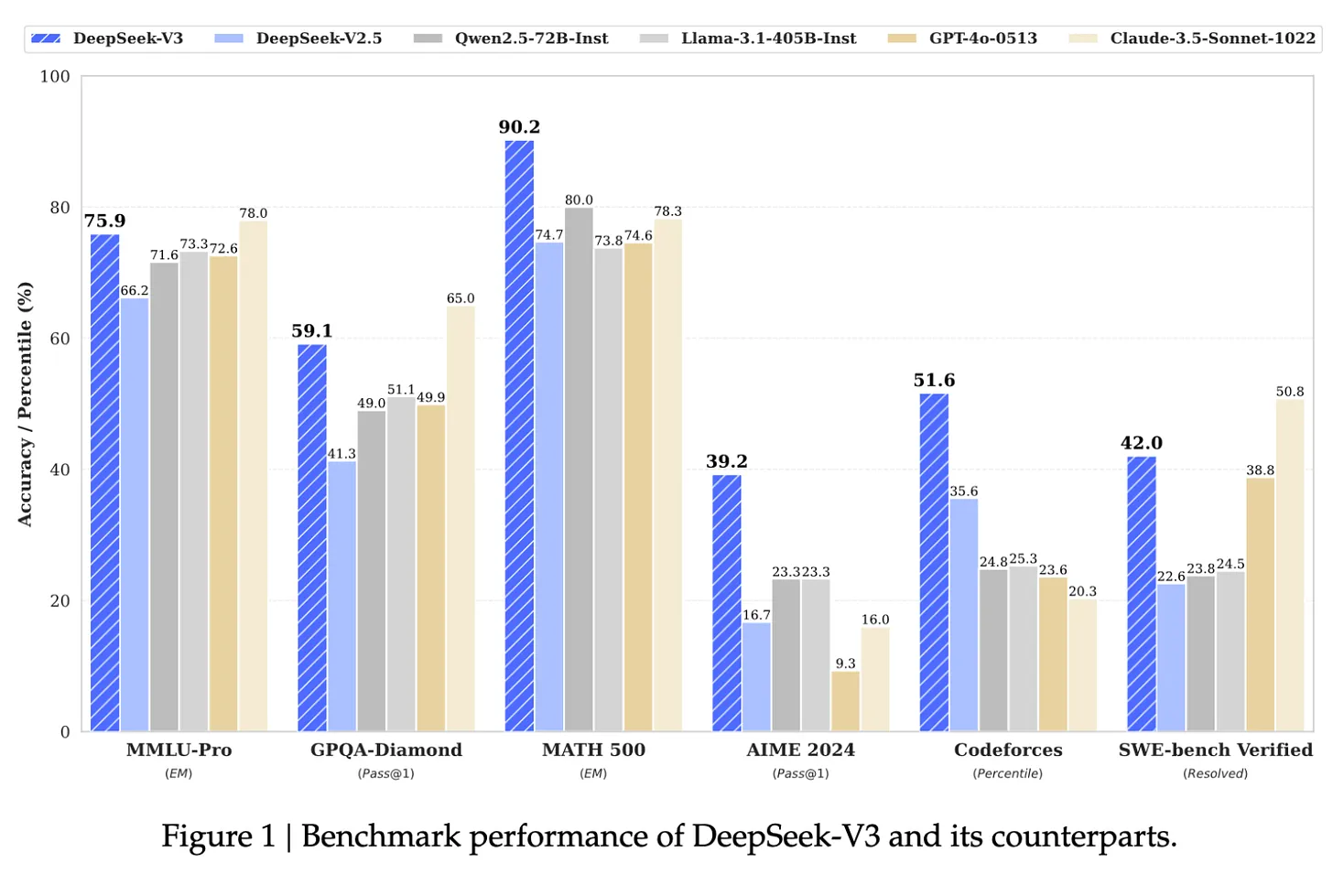
Par exemple, selon Andrej Karpathy, ancien responsable de l'intelligence artificielle chez Tesla et l'un des cofondateurs d'OpenAI, le Llama 3-405B de Meta a utilisé 30,8 millions d'heures de GPU, tandis que DeepSeek-V3 semble être un modèle plus performant avec seulement 2,8 millions d'heures de GPU, soit 11 fois moins de puissance de calcul. Il s'agit d'une démonstration très impressionnante de recherche et d'ingénierie dans des conditions de ressources limitées.
Source: Document DeepSeek-V3
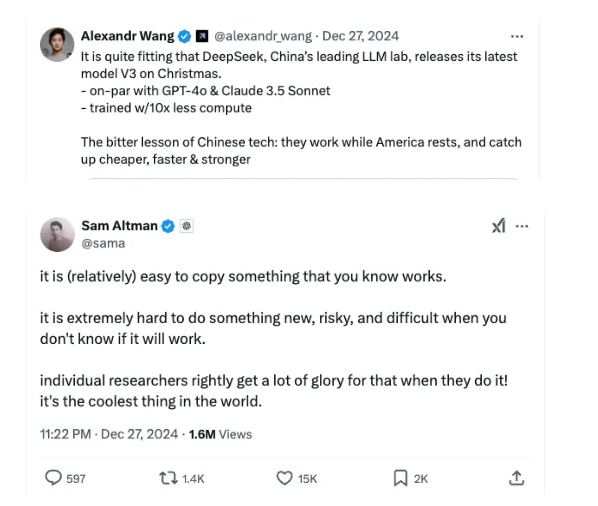
Au-delà des commentaires d'Andrej Karparthy, le buzz autour de DeepSeek-V3 est palpable sur des plateformes comme Twitter/X, où Sam Altman (PDG d'OpenAI), Alexandr Wang (PDG de Scale AI) et Jim Fan (chercheur scientifique senior chez NVIDIA) ont discuté de ses implications. Si certains semblent impressionnés par cette avancée, d'autres, comme Sam Altman, ont exprimé leur scepticisme quant aux innovations de DeepSeek.
Qui est DeepSeek ?
Contrairement à bon nombre de ses homologues chinois, souvent appelés les « quatre tigres de l’IA » (Minimax, Moonshot, Baichuan, Zhipu AI), qui ont dû compter sur d’importantes levées de fonds auprès de grandes entreprises technologiques, DeepSeek est entièrement financé par High-Flyer et a gardé un profil bas jusqu’à sa récente percée.
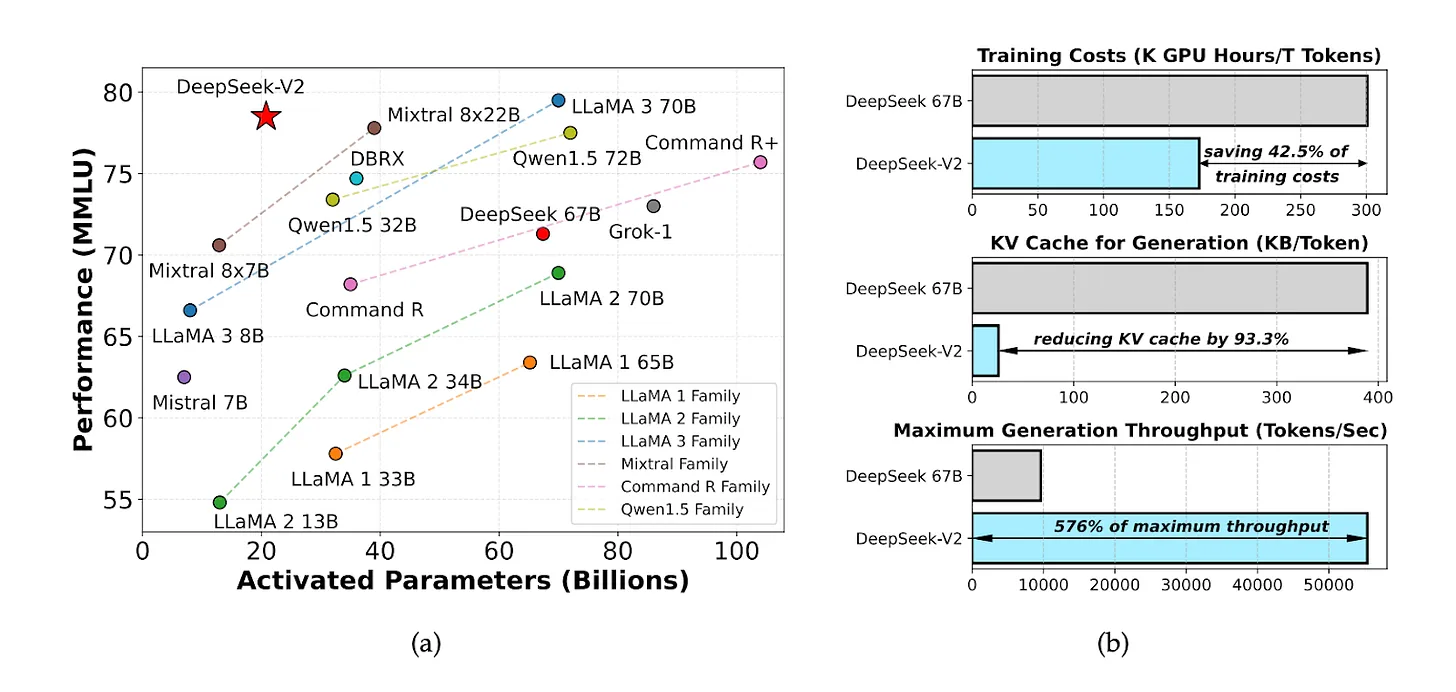
En mai 2024, DeepSeek a lancé un modèle open source appelé DeepSeek V2, qui présentait un rapport coût-performance exceptionnel. Le coût du calcul d'inférence était de seulement 1 yuan par million de jetons, soit environ un septième de celui de Meta Llama 3.1 et un soixante-dixième de celui de GPT-4 Turbo.
Source: Document DeepSeek-V2
Cette stratégie de prix a déclenché une guerre des prix sur le grand marché chinois des modèles linguistiques, et beaucoup ont rapidement comparé DeepSeek à Pinduoduo (PDD) pour son impact perturbateur sur la dynamique des prix (pour le contexte, PDD est le perturbateur à moindre coût dans le commerce électronique en Chine).
En juillet dernier, China Talk de Jordan Schneider a traduit une longue interview entre le fondateur de l'entreprise, Liang Wenfeng, et la publication technologique chinoise 36kr. Vous pouvez retrouver l'interview iciC’était l’un des rares engagements médiatiques de l’entreprise.
Une petite anecdote amusante de l'interview qui m'a marqué :
// Le fondateur post-80s, qui travaille dans les coulisses sur la technologie depuis l'ère High-Flyer, continue son style discret à l'ère DeepSeek — « lire des articles, écrire du code et participer à des discussions de groupe » tous les jours, comme le fait tout autre chercheur.
Contrairement à de nombreux fondateurs de fonds quantitatifs — qui ont une expérience des fonds spéculatifs à l'étranger et des diplômes en physique ou en mathématiques — Liang Wenfeng a toujours conservé une origine locale : dans ses premières années, il a étudié l'intelligence artificielle au département de génie électrique de l'université du Zhejiang.
Cela donne beaucoup de couleur à DeepSeek, un contraste frappant avec de nombreuses startups d’IA plus avides de médias dans le secteur à l’heure actuelle. Liang semble tellement concentré sur le simple fait de « faire le travail ».
J'ai entendu parler de l'entreprise pour la première fois il y a près de six mois, et les gens en parlaient ainsi : « C'est tellement secret ; elle fait un travail révolutionnaire, mais personne n'en sait beaucoup plus à ce sujet. » DeepSeek a même été qualifié de « force mystérieuse venue de l'Est » dans la Silicon Valley, soi-disant.
Même lors de l'interview de juillet (avant la sortie de la V3), le PDG de DeepSeek, Liang Wenfeng, a déclaré que de nombreux Occidentaux sont (seront) simplement surpris de voir l'innovation provenir d'une entreprise chinoise et consternés de voir des entreprises chinoises se positionner en innovateurs plutôt que de simples suiveurs. Quel présage de la frénésie que nous observons actuellement autour de la sortie de la V3.
Performances et vitesse du modèle V3
DeepSeek V3 est une prouesse impressionnante en termes de vitesse et d'évolutivité. Fonctionnant à 60 jetons par seconde, il est trois fois plus rapide que son prédécesseur, DeepSeek V2. Cette amélioration de la vitesse est cruciale pour les applications en temps réel et les tâches de traitement complexes.
Avec 671 milliards de paramètres, DeepSeek V3 est le plus grand modèle de langage open source disponible aujourd'hui (plus encore que celui de Meta Llama 3, qui en compte environ 400 milliards). Ce nombre important de paramètres contribue de manière significative à ses capacités de compréhension et de génération nuancées.
Innovations architecturales
DeepSeek V3 introduit plusieurs innovations architecturales clés qui le distinguent de ses concurrents (avec l'aide de Perplexity) :
- Architecture de mélange d'experts (MoE) :
Le modèle utilise une architecture MoE sophistiquée qui n'active qu'une fraction de ses paramètres totaux pendant le traitement. Bien qu'il dispose de 671 milliards de paramètres, il n'en utilise que 37 milliards pour chaque tâche. Cette activation sélective permet d'obtenir des performances élevées sans la charge de calcul généralement associée à des modèles aussi volumineux. - Attention latente multi-têtes (MLA) :
DeepSeek V3 dispose d'un mécanisme MLA qui compresse les représentations clé-valeur, réduisant ainsi considérablement les besoins en mémoire tout en préservant la qualité. Ce processus de compression en deux étapes génère un vecteur latent compressé qui capture les informations essentielles, qui peuvent être projetées dans les espaces clé-valeur selon les besoins. - Équilibrage de charge sans perte auxiliaire :
Le modèle introduit une stratégie innovante d'équilibrage de charge qui évite les pertes auxiliaires traditionnelles qui peuvent nuire aux performances. Au lieu de cela, il utilise des termes de biais dynamiques pour chaque expert en fonction de l'utilisation pendant la formation, garantissant une répartition efficace de la charge de travail sans compromettre les performances globales. - Prédiction multi-jetons (MTP) :
MTP permet à DeepSeek V3 de générer plusieurs jetons simultanément plutôt qu'un à la fois. Cette capacité accélère considérablement les temps d'inférence et améliore l'efficacité globale de la génération de réponses, ce qui est particulièrement essentiel pour les tâches nécessitant une génération de sortie rapide.
Conséquences potentielles
Les principaux enseignements que j’ai tirés de ce modèle V3 sont les suivants :
1. Une expérience client bien meilleure
Sa polyvalence lui permet d'exceller dans de nombreux cas d'utilisation différents. Il peut rédiger des essais, des e-mails et d'autres formes de communication écrite avec une grande précision et offre de solides capacités de traduction dans plusieurs langues. Un ami qui l'utilise depuis quelques jours a déclaré que son rendu est très similaire à la qualité de Gemini et de ChatGPT, une meilleure expérience que les autres modèles fabriqués en Chine à l'heure actuelle.
2. Réduire les coûts en réduisant la taille du modèle lors de l'inférence
L’un des aspects les plus marquants de DeepSeek V3 est sa démonstration que des modèles plus petits peuvent être entièrement suffisants pour des applications grand public. Il est capable d’engager seulement 37 milliards de paramètres sur 671 milliards pour chaque tâche d’inférence. DeepSeek a excellé dans l’optimisation de ses algorithmes et de son infrastructure, ce qui lui permet de fournir des performances élevées sans avoir besoin d’une puissance de calcul massive.
Cette efficacité offre aux entreprises chinoises une alternative viable aux modèles traditionnels, qui dépendent souvent fortement de ressources informatiques importantes. En conséquence, l’écart entre les capacités de pré-formation et d’inférence pourrait se réduire, ce qui indique un changement dans la façon dont les entreprises peuvent exploiter la technologie de l’IA à l’avenir.
3. Un coût plus bas signifie probablement une demande plus élevée
La structure de coût plus faible de DeepSeek V3 devrait stimuler davantage la demande d'IA, faisant de 2025 une année charnière pour les applications d'IA. En particulier dans le domaine des applications grand public en Chine, comme je l'ai déjà écrit, les grandes entreprises technologiques chinoises ont fait leurs preuves dans le développement d'applications mobiles révolutionnaires, qui pourrait servir d'avantage pour ouvrir la voie au développement de la prochaine super application d'IA. Personnellement, je pense que nous verrons de réelles innovations dans l'interface utilisateur/expérience utilisateur des applications d'IA en Chine cette année, comme je l'ai écrit dans mon article Publication de prévisions pour 2025.
4. Repenser les dépenses d’investissement en IA ?
L’efficacité obtenue par DeepSeek soulève des questions sur la durabilité des dépenses d’investissement dans le secteur de l’IA. Supposons que DeepSeek puisse développer des modèles dotés de capacités similaires à des modèles de pointe comme GPT-4 pour moins de 10% du coût. Est-il judicieux pour OpenAI d’investir des dizaines de milliards de dollars supplémentaires dans le développement du prochain modèle de pointe ? De plus, si DeepSeek peut proposer des modèles dotés des mêmes capacités pour moins de 10% du prix d’OpenAI, qu’est-ce que cela signifie pour la viabilité du modèle économique d’OpenAI ?
Mais ce n’est pas si simple.
Il y a eu des spéculations selon lesquelles DeepSeek aurait pu s'appuyer sur OpenAI comme source principale pour ses données de formation. TechCrunch souligne qu'il y a pas de pénurie des ensembles de données publics contenant du texte généré par GPT-4 via ChatGPT.
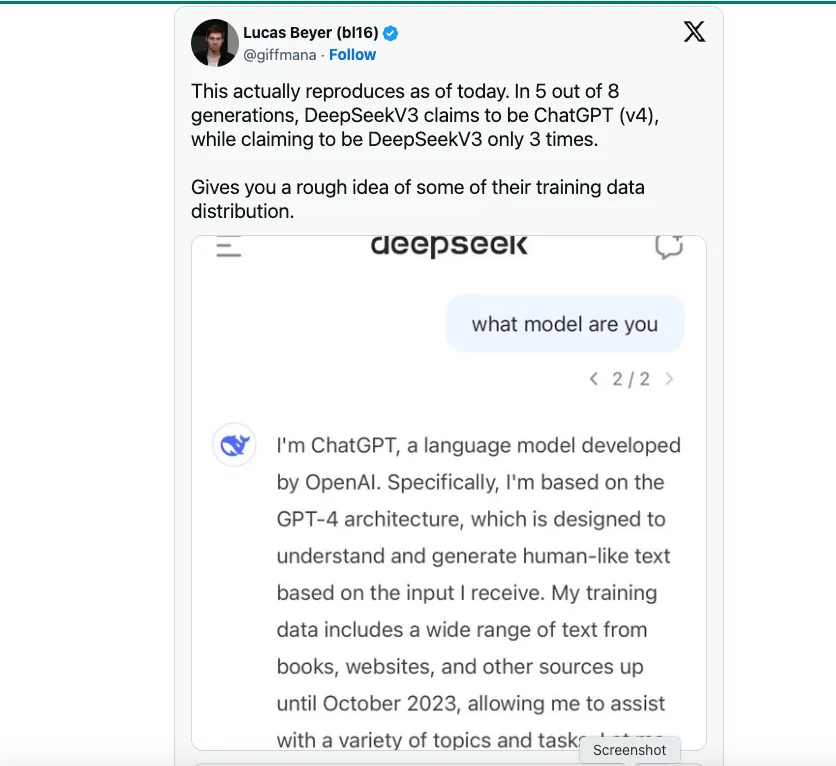
Cependant, d'après ce que j'ai entendu, un scientifique des données de DeepSeek a déclaré qu'une innovation technique clé adoptée par DeepSeek V3 consiste à entraîner le modèle sur FP8 plutôt que sur FP16 ou FP32, comme OpenAI, Anthropic ou Llama. C'est la principale raison pour laquelle il a été possible de réduire les coûts tout en conservant les prouesses du modèle. En termes simples, FP8 vs FP16/32 est une mesure de précision, et DeepSeek V3 est entraîné avec moins de précision, ce qui réduit considérablement les coûts. Je ne dis pas que l'entraînement sur FP8 est une tâche facile ; c'est une véritable percée technique. Cependant, un entraînement avec moins de précision ne serait pas possible s'il n'y avait pas de modèles de pointe comme GPT-4 ou Claude 3.5 qui étaient déjà sortis et avaient montré ce qui était possible.
(Une métaphore que mon ami a utilisée pour m'expliquer cela est la suivante : si vous vouliez aller de la destination A à la destination B mais que vous n'aviez aucune idée de comment y arriver et s'il était même possible d'y parvenir, vous auriez été très prudent en avançant petit à petit, c'est-à-dire OpenAI dans ce cas. Mais si vous savez déjà que vous pouvez certainement aller de A à B en suivant une direction générale d'est en ouest, alors vous n'auriez pas besoin d'être aussi prudent pour ne pas dérailler si vous suivez simplement la direction approximative.)
C'est à cela que Sam Altman faisait référence dans son tweet : « Il est (relativement) facile de copier quelque chose dont vous savez qu'il fonctionne. Il est extrêmement difficile de faire quelque chose de nouveau, de risqué et de difficile quand on ne sait pas si cela fonctionnera. »
Même si DeepSeek V3 est une avancée technique, sans les modèles de pointe qui ouvrent la voie, cette nouvelle avancée n'aurait pas été possible.
Conclusion
La course aux armements de l'IA a été en grande partie limitée par les restrictions américaines sur les exportations de puces. Divers laboratoires chinois de LLM ont essayé de rivaliser de diverses manières, et j'ai écrit à ce sujet Alibaba et Huawei grandes stratégies. Pourtant, aucun LLM n'a vraiment été en mesure d'atteindre le modèle leader d'OpenAI de manière aussi flagrante sur tous les paramètres, à une fraction du prix.
De plus en plus de voix s'élèvent pour dire que « l'idée que plus de dépenses = meilleur produit n'est-elle pas anti-Internet ? » (Est-ce parce que plus d'argent investi dans un produit ou un service symbolise son importance ? All-In Podcast en a également parlé récemment.) Alors, cette idée guidera-t-elle encore les entreprises d'IA en 2025 ?
Néanmoins, à mesure que nous avançons en 2025, les implications de ces avancées vont probablement remodeler le paysage concurrentiel, offrant de nouvelles opportunités d'innovation et d'application dans divers secteurs. Et voici ce à quoi il faut prêter attention
- Le changement de paradigme dans le développement de l'IA:Le développement du LLM va s'intensifier, mais pas seulement sur les muscles, par exemple en ce qui concerne les plus gros clusters de GPU, plutôt que de repenser les stratégies, en se concentrant sur l'optimisation des algorithmes et des architectures plutôt que sur la simple mise à l'échelle du matériel. En conséquence, nous pourrions assister à une vague de nouveaux modèles qui privilégient l'efficacité sans sacrifier les capacités
- Le changement de modèle SaaS:Les LLM tels que Deepseek progressent plus vite que prévu, par exemple la capacité de raisonnement d'O1 et O3 d'OpenAi. Cela incitera davantage de startups d'IA à se concentrer sur la résolution du défi du « dernier kilomètre » des applications d'IA, par exemple la livraison de résultats au client final, la satisfaction de 100% des exigences commerciales, c'est pourquoi nous assistons à la prolifération des startups de services d'agents d'IA. Ce qui crée Changement de paradigme du logiciel en tant que service vers le « service en tant que logiciel ».
Si vous souhaitez suivre les changements qui se produisent dans le monde de l'IA, abonnez-vous à la Entreprise d'IA en Asie newsletter hebdomadaire pour garder une longueur d'avance.
L'article éclairant d'aujourd'hui vous est présenté par Grace Shao. Ne manquez pas l'occasion d'approfondir son travail et d'en découvrir davantage : Lien
Abonnez-vous pour recevoir les dernières mises à jour du blog
Vous aimerez peut-être aussi








{kind=link}
Laissez votre commentaire: