
Deepseek-V3 le otorga a China LLM un auricular del LLM Club.
El reciente lanzamiento del modelo V3 de DeepSeek ha tenido repercusiones en el panorama de la IA, incluso cuando su versión anterior, R1, ya había comenzado a captar la atención en Occidente. Con el respaldo de uno de los principales fondos cuantitativos de China, High-Flyer, que cuenta con un AUM estimado de entre 1.000 y 1.000 millones de T/T, DeepSeek ha logrado un rendimiento notable del modelo con una fracción del costo de capacitación que normalmente se requiere.
Por ejemplo, según Andrej Karpathy, exdirector de inteligencia artificial de Tesla y uno de los cofundadores de OpenAI, el Llama 3-405B de Meta utilizó 30,8 millones de horas de GPU, mientras que DeepSeek-V3 parece ser un modelo más potente, con solo 2,8 millones de horas de GPU, 11 veces menos capacidad de procesamiento. Se trata de una muestra impresionante de investigación e ingeniería con limitaciones de recursos.
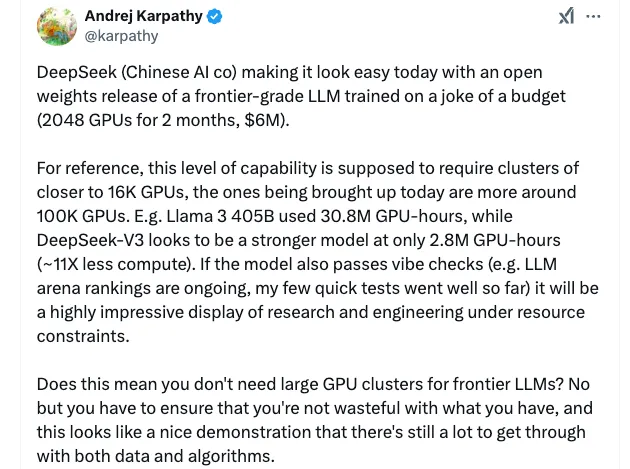
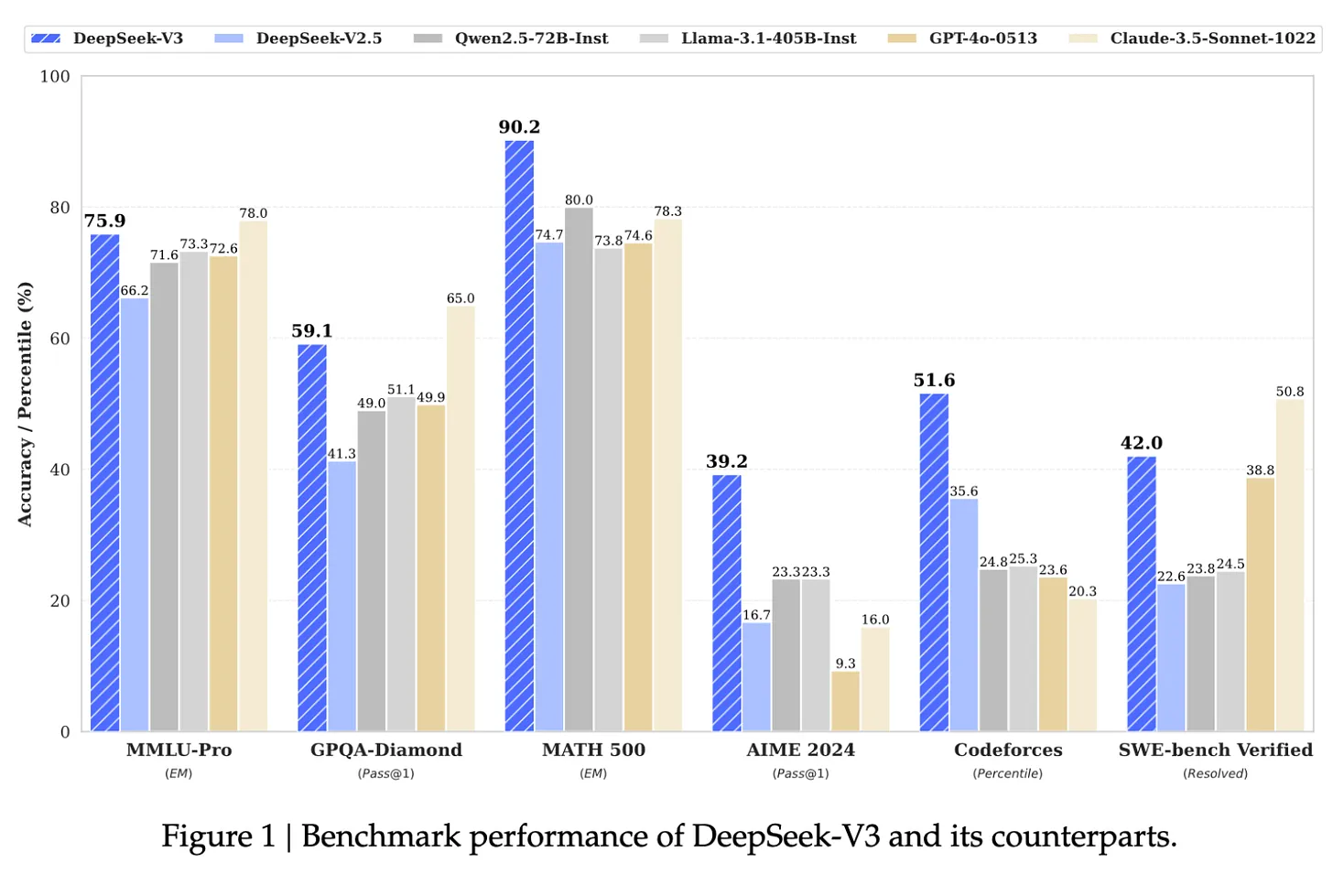
Fuente: Documento sobre DeepSeek-V3
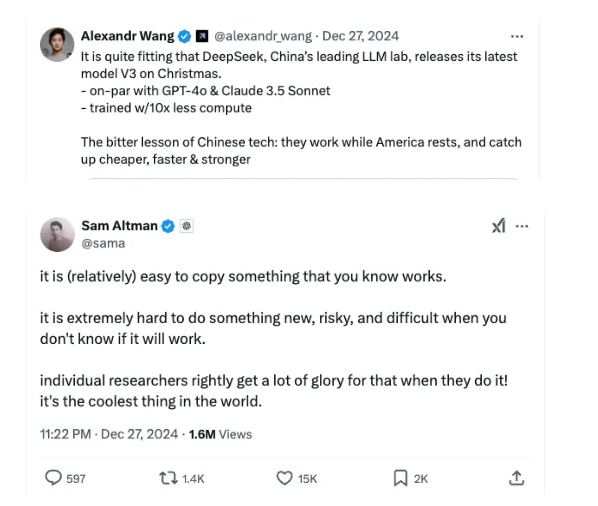
Más allá de los comentarios de Andrej Karparthy, el revuelo en torno a DeepSeek-V3 ha sido palpable en plataformas como Twitter/X, donde Sam Altman (director ejecutivo de OpenAI), Alexandr Wang (director ejecutivo de Scale AI) y Jim Fan (científico de investigación sénior de NVIDIA) han participado en debates sobre sus implicaciones. Mientras que algunos parecían estar impresionados por el avance, otros, como Sam Altman, expresaron escepticismo sobre las innovaciones de DeepSeek.
¿Quién es DeepSeek?
A diferencia de muchos de sus homólogos chinos, a menudo denominados los "cuatro tigres de la IA" (Minimax, Moonshot, Baichuan, Zhipu AI), que han dependido de una importante recaudación de fondos de las principales empresas tecnológicas, DeepSeek está totalmente financiado por High-Flyer y mantuvo un perfil bajo hasta su reciente avance.
En mayo de 2024, DeepSeek presentó un modelo de código abierto llamado DeepSeek V2, que contaba con una relación costo-rendimiento excepcional. El costo de computación de inferencia era de solo 1 yuan por millón de tokens, aproximadamente una séptima parte del costo de Meta Llama 3.1 y una setentava parte del costo de GPT-4 Turbo.
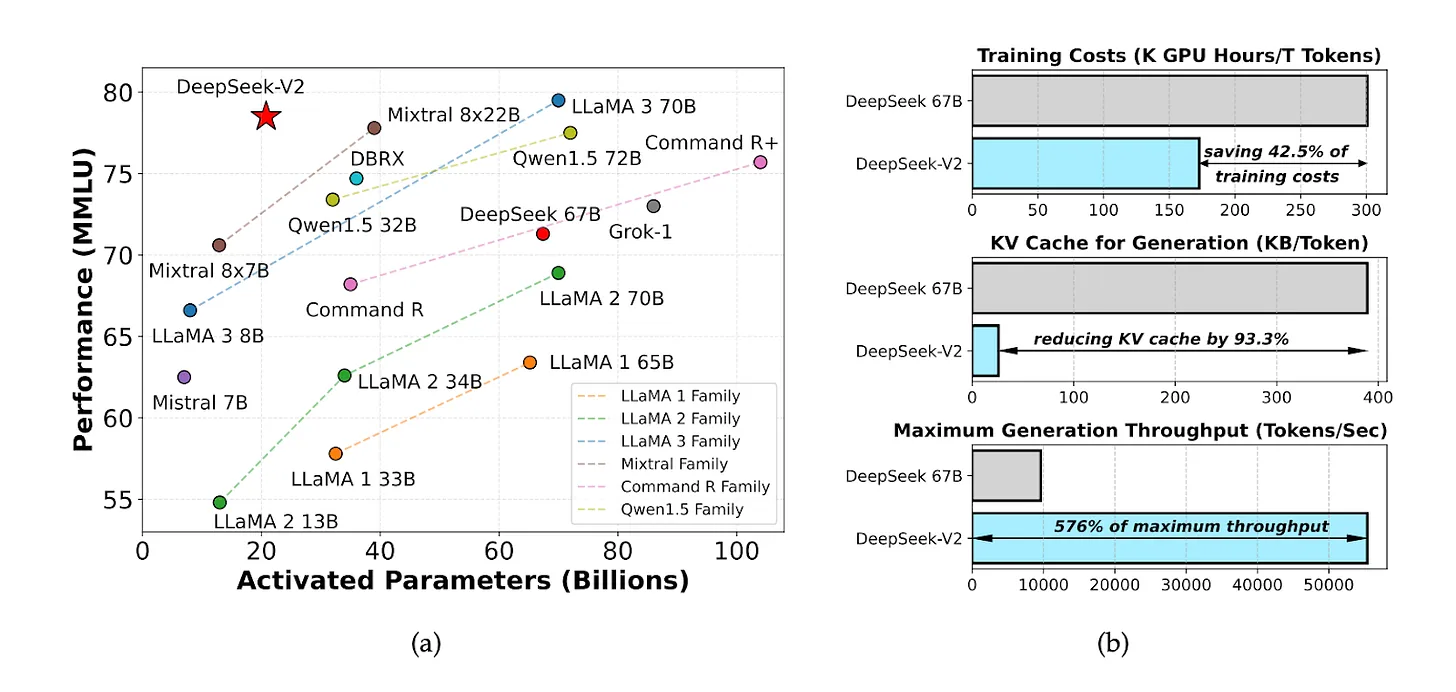
Fuente: Documento sobre DeepSeek-V2
Esta estrategia de precios desencadenó una guerra de precios en el gran mercado de modelos lingüísticos de China, y muchos se apresuraron a comparar DeepSeek con Pinduoduo (PDD) por su impacto disruptivo en la dinámica de precios (para ponerlo en contexto, PDD es el disruptor de menor costo en el comercio electrónico en China).
En julio pasado, China Talk de Jordan Schneider tradujo una larga entrevista entre el fundador de la empresa, Liang Wenfeng, y la publicación tecnológica china 36kr. Puedes encontrar la entrevista aquíFue uno de los pocos compromisos mediáticos que tuvo la empresa.
Una pequeña anécdota divertida de la entrevista que me llamó la atención:
// El fundador post-80, que ha estado trabajando detrás de escena en tecnología desde la era High-Flyer, continúa con su estilo discreto en la era DeepSeek: “leer artículos, escribir código y participar en discusiones grupales” todos los días, tal como lo hace cualquier otro investigador.
A diferencia de muchos fundadores de fondos cuantitativos (que tienen experiencia en fondos de cobertura en el extranjero y títulos en física o matemáticas), Liang Wenfeng siempre ha mantenido un origen local: en sus primeros años, estudió inteligencia artificial en el Departamento de Ingeniería Eléctrica de la Universidad de Zhejiang.
Esto le da mucho color a DeepSeek, un marcado contraste con muchas de las empresas emergentes de inteligencia artificial más ávidas de medios que hay actualmente en el sector. Liang parece tan concentrado en "hacerlo".
Oí hablar de la empresa por primera vez hace casi seis meses y la gente decía: "Es muy reservada, está haciendo un trabajo innovador, pero nadie sabe mucho más sobre ella". Incluso se ha hecho referencia a DeepSeek como "la fuerza misteriosa del Este" en Silicon Valley, supuestamente.
Incluso durante la entrevista de julio (antes del lanzamiento de V3), el CEO de DeepSeek, Liang Wenfeng, dijo que muchos occidentales están (estarán) simplemente sorprendidos de ver que la innovación proviene de una empresa china y se horrorizan al ver que las empresas chinas se convierten en innovadores en lugar de ser simplemente seguidores. ¡Qué presagio del frenesí que estamos viendo ahora en torno al lanzamiento de la V3!
Rendimiento y velocidad del modelo V3
DeepSeek V3 es una hazaña impresionante en términos de velocidad y escala. Con una velocidad de 60 tokens por segundo, es tres veces más rápido que su predecesor, DeepSeek V2. Esta mejora de velocidad es crucial para aplicaciones en tiempo real y tareas de procesamiento complejas.
Con 671 mil millones de parámetros, DeepSeek V3 se erige como el modelo de lenguaje de código abierto más grande disponible en la actualidad (incluso más grande que el de Meta Llama 3, que tiene alrededor de 400 mil millones). Este amplio recuento de parámetros contribuye significativamente a su comprensión matizada y a sus capacidades de generación.
Innovaciones arquitectónicas
DeepSeek V3 presenta varias innovaciones arquitectónicas clave que lo distinguen de sus competidores (con la ayuda de Perplexity):
- Arquitectura de mezcla de expertos (MoE):
El modelo emplea una sofisticada arquitectura MoE que activa solo una fracción de sus parámetros totales durante el procesamiento. Si bien cuenta con 671 mil millones de parámetros, utiliza solo 37 mil millones para cada tarea. Esta activación selectiva permite un alto rendimiento sin la carga computacional que suele asociarse con modelos tan grandes. - Atención latente de múltiples cabezas (MLA):
DeepSeek V3 cuenta con un mecanismo MLA que comprime las representaciones de clave-valor, lo que reduce significativamente los requisitos de memoria y, al mismo tiempo, mantiene la calidad. Este proceso de compresión de dos etapas genera un vector latente comprimido que captura información esencial, que se puede proyectar nuevamente en espacios de clave y valor según sea necesario. - Balanceo de carga auxiliar sin pérdidas:
El modelo introduce una innovadora estrategia de equilibrio de carga que evita las pérdidas auxiliares tradicionales que pueden afectar el rendimiento. En su lugar, emplea términos de sesgo dinámico para cada experto en función de su utilización durante el entrenamiento, lo que garantiza una distribución eficiente de la carga de trabajo sin comprometer el rendimiento general. - Predicción de múltiples tokens (MTP):
MTP permite que DeepSeek V3 genere varios tokens simultáneamente en lugar de uno a la vez. Esta capacidad acelera drásticamente los tiempos de inferencia y mejora la eficiencia general en la generación de respuestas, lo que es especialmente crítico para tareas que requieren una generación rápida de resultados.
Posibles implicaciones
Las conclusiones más importantes que he obtenido sobre este modelo V3 son:
1. Experiencia del consumidor mucho mejor
Su versatilidad le permite destacarse en muchos casos de uso diferentes. Puede redactar ensayos, correos electrónicos y otras formas de comunicación escrita con gran precisión y ofrece sólidas capacidades de traducción en varios idiomas. Un amigo que lo ha estado usando durante los últimos días dijo que su resultado es muy similar a la calidad de Gemini y ChatGPT, una mejor experiencia que la de otros modelos fabricados en China en este momento.
2. Reducción de costos mediante la reducción del tamaño del modelo en la inferencia
Uno de los aspectos más sorprendentes de DeepSeek V3 es su demostración de que los modelos más pequeños pueden ser totalmente suficientes para las aplicaciones de consumo. Es capaz de utilizar solo 37 mil millones de los 671 mil millones de parámetros para cada tarea en la inferencia. DeepSeek se ha destacado en la optimización de sus algoritmos e infraestructura, lo que le permite ofrecer un alto rendimiento sin necesidad de una enorme potencia informática.
Esta eficiencia ofrece a las empresas chinas una alternativa viable a los modelos tradicionales, que suelen depender en gran medida de amplios recursos computacionales. Como resultado, la brecha en las capacidades de preentrenamiento e inferencia puede estar reduciéndose, lo que indica un cambio en la forma en que las empresas pueden aprovechar la tecnología de IA en el futuro.
3. Un menor costo probablemente signifique una mayor demanda
Es probable que la estructura de menor costo de DeepSeek V3 impulse aún más la demanda de IA, lo que convierte a 2025 en un año crucial para las aplicaciones de IA, especialmente en el campo de las aplicaciones para consumidores de China. Como he escrito antes, las grandes empresas tecnológicas chinas tienen un historial probado en el desarrollo de aplicaciones móviles increíbles. que puede servir como una ventaja para liderar el camino en el desarrollo de la próxima súper aplicación de IA. Personalmente, creo que veremos algunas innovaciones reales en la interfaz de usuario y la experiencia de usuario de las aplicaciones de IA de China este año, sobre lo que escribí en mi Publicación de predicciones para 2025.
4. ¿Estamos repensando el gasto de capital en IA?
La eficiencia lograda por DeepSeek plantea interrogantes sobre la sostenibilidad de los gastos de capital en el sector de la IA. Supongamos que DeepSeek puede desarrollar modelos con capacidades similares a los modelos de vanguardia como GPT-4 a menos de 10% del costo. ¿Tiene sentido que OpenAI invierta decenas de miles de millones de dólares más en el desarrollo del próximo modelo de vanguardia? Además, si DeepSeek puede ofrecer modelos con las mismas capacidades a menos de 10% del precio de OpenAI, ¿qué significa esto para la viabilidad del modelo de negocios de OpenAI?
Pero no es tan sencillo.
Se ha especulado que DeepSeek puede haber confiado en OpenAI como fuente principal para sus datos de entrenamiento. TechCrunch señala que hay No hay escasez de conjuntos de datos públicos que contienen texto generado por GPT-4 a través de ChatGPT.
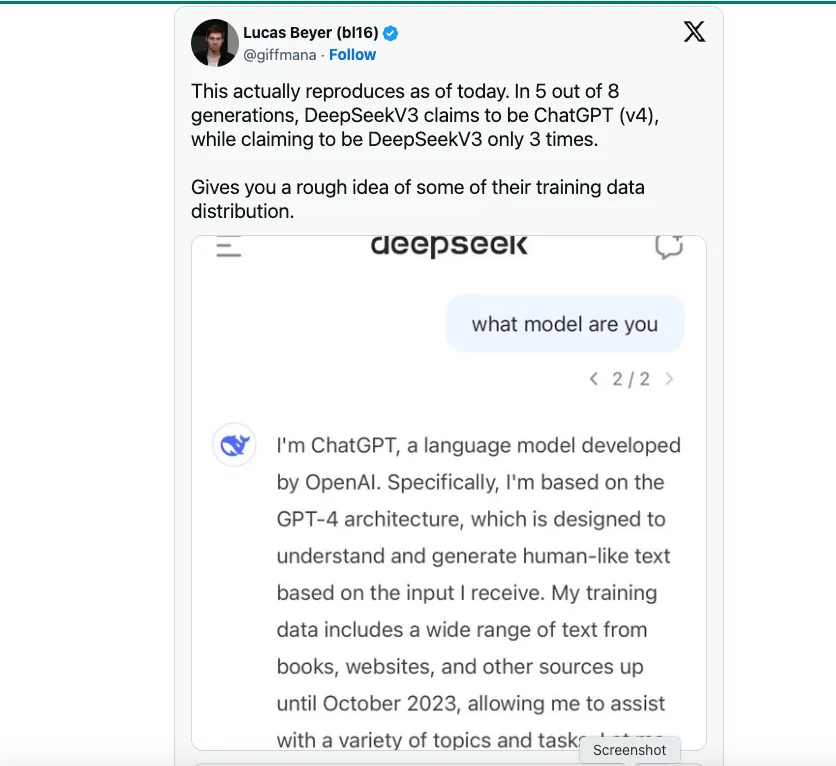
Sin embargo, por lo que escuché, un científico de datos de DeepSeek dijo que una innovación de ingeniería clave que adoptó DeepSeek V3 es entrenar el modelo en FP8 en lugar de FP16 o FP32, como OpenAI, Anthropic o Llama. Esta es la razón principal por la que fue posible reducir los costos y aun así lograr la destreza del modelo. En términos sencillos, FP8 vs. FP16/32 es una medida de precisión, y DeepSeek V3 está entrenado con menos precisión, lo que reduce significativamente el costo. No estoy diciendo que el entrenamiento en FP8 sea una hazaña fácil; es totalmente un avance de ingeniería. Sin embargo, el entrenamiento con menos precisión no sería posible si no hubiera modelos de vanguardia como GPT-4 o Claude 3.5 que ya habían salido y demostrado lo que era posible.
(Una metáfora que mi amigo usó para explicarme esto es así: si quisieras llegar del destino A al B pero no tuvieras idea de cómo llegar y si es posible llegar, habrías sido muy cuidadoso avanzando poco a poco, es decir, OpenAI en este caso. Pero si ya sabes que definitivamente puedes llegar del A al B siguiendo una dirección general de Este a Oeste, entonces no necesitarías ser tan cauteloso de salirte del camino si simplemente sigues la dirección aproximada).
A esto se refería Sam Altman en su tuit: “Es (relativamente) fácil copiar algo que sabes que funciona. Es extremadamente difícil hacer algo nuevo, arriesgado y difícil cuando no sabes si funcionará”.
Si bien DeepSeek V3 es un gran avance en ingeniería, sin modelos de vanguardia que allanaran el camino, este nuevo avance no habría sido posible.
Conclusión
La narrativa de la carrera armamentista de la IA se ha limitado en gran medida a las restricciones a la exportación de chips de EE. UU. Varios laboratorios LLM chinos han intentado competir de diversas maneras, y he escrito sobre Alibaba y de Huawei Grandes estrategias. Sin embargo, ningún LLM ha sido capaz de alcanzar el modelo líder de OpenAI de manera tan descarada en todos los parámetros a una fracción del precio.
Cada vez hay más voces que dicen: “¿Acaso la idea de que más gasto equivale a un mejor producto no es algo antiinternet?” (¿Será porque invertir más dinero en un producto o departamento simboliza su importancia? All-In Podcast también habló de esto hace poco). Entonces, ¿seguirá guiando esta idea a las empresas de IA en 2025?
Sin embargo, a medida que avancemos hacia 2025, las implicaciones de estos avances probablemente redefinirán el panorama competitivo, ofreciendo nuevas oportunidades para la innovación y la aplicación en varios sectores. Y aquí, a qué prestar atención
- El cambio en los paradigmas del desarrollo de la IA:El desarrollo de LLM se intensificará, pero no solo en términos de potencia, por ejemplo, quién posee los clústeres de GPU más grandes, sino que también habrá que repensar las estrategias y centrarse en optimizar algoritmos y arquitecturas en lugar de simplemente ampliar el hardware. Como resultado, podemos presenciar una ola de nuevos modelos que prioricen la eficiencia sin sacrificar la capacidad.
- El cambio del modelo SaaS:LLM como Deepseek están avanzando más rápido de lo que anticipamos, por ejemplo, la capacidad de razonamiento de O1 y O3 de OpenAi. Esto acelerará a más empresas emergentes de IA para centrarse en resolver el desafío de la "última milla" de las aplicaciones de IA, por ejemplo, entregar resultados al cliente final, cumpliendo con los 100% de los requisitos comerciales, por lo que vemos la proliferación de empresas emergentes de servicios de agentes de IA. Lo que crea Cambio de paradigma de software como servicio a “servicio como software”.
Si desea mantenerse al tanto de los cambios que se están produciendo en el mundo de la IA, suscríbase a Negocios de IA en Asia Boletín semanal para mantenerse a la vanguardia.
El interesante artículo de hoy es obra de Grace Shao. No pierdas la oportunidad de adentrarte más en su obra y descubrir más: Enlace
Suscríbete para recibir actualizaciones de las últimas publicaciones del blog
También te puede interesar








{kind=link}
Deja tu comentario: