
Deepseek-V3 verschafft China LLM ein Headset des LLM Clubs.
Die kürzliche Einführung des V3-Modells von DeepSeek hat in der KI-Landschaft für Aufsehen gesorgt, obwohl die frühere Version R1 im Westen bereits für Aufsehen gesorgt hatte. Unterstützt von einem der führenden quantitativen Fonds Chinas, High-Flyer, der ein geschätztes verwaltetes Vermögen von $5,5 bis $8 Milliarden hat, hat DeepSeek eine bemerkenswerte Modellleistung mit einem Bruchteil der normalerweise erforderlichen Trainingskosten erreicht.
Laut Andrej Karpathy, dem ehemaligen KI-Chef von Tesla und Mitbegründer von OpenAI, verbrauchte Metas Llama 3-405B beispielsweise 30,8 Millionen GPU-Stunden, während DeepSeek-V3 mit nur 2,8 Millionen GPU-Stunden und 11-mal weniger Rechenleistung ein leistungsstärkeres Modell zu sein scheint. Dies ist eine äußerst beeindruckende Demonstration von Forschung und Entwicklung unter Ressourcenbeschränkungen.
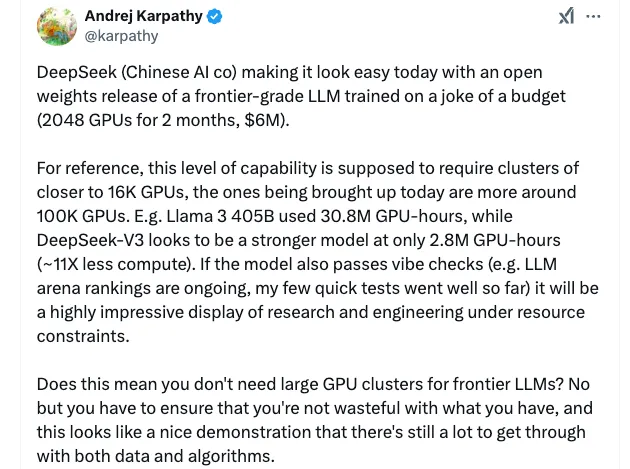
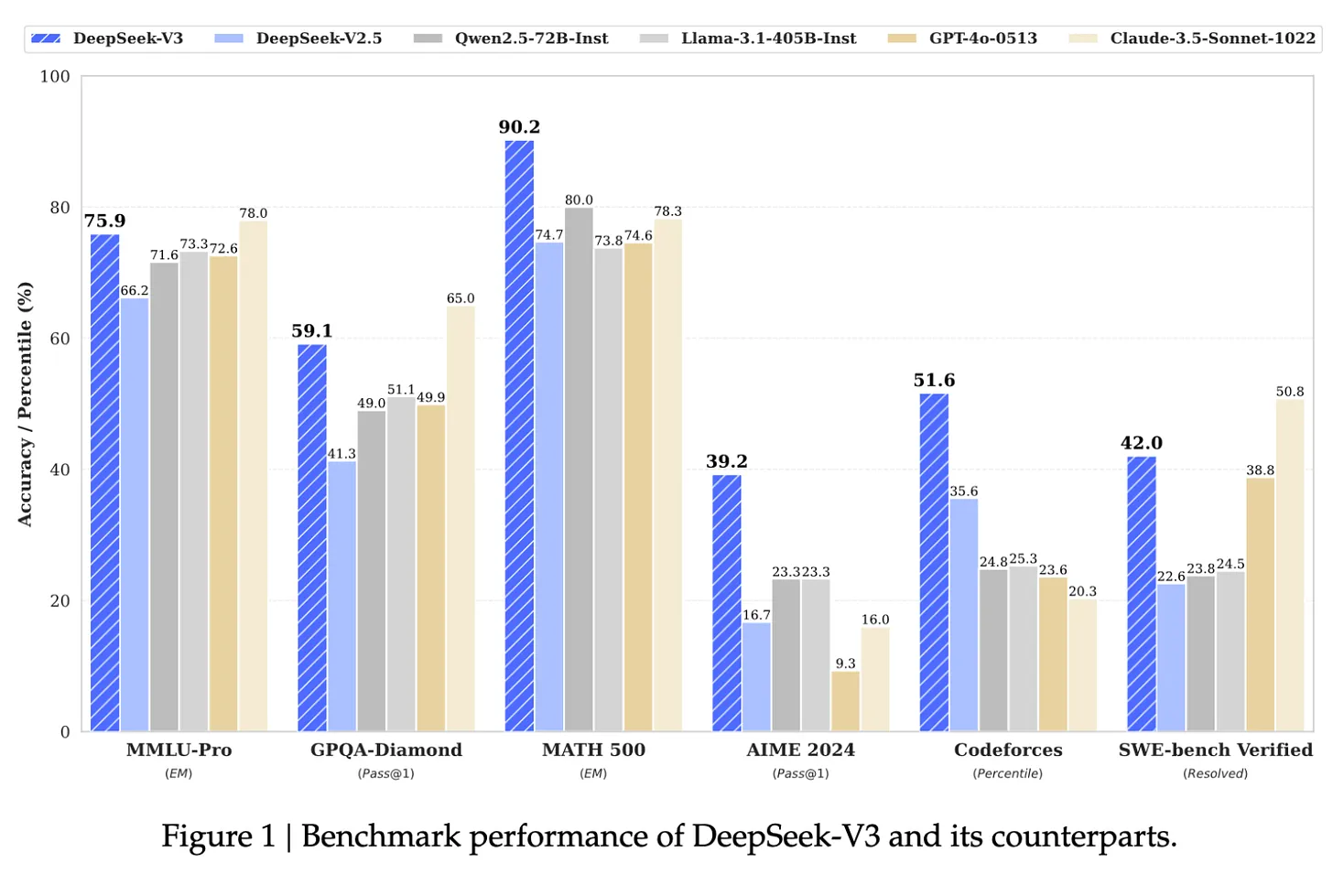
Quelle: DeepSeek-V3-Dokument
Über Andrej Karparthys Kommentare hinaus war die Aufregung um DeepSeek-V3 auf Plattformen wie Twitter/X spürbar, wo Sam Altman (CEO von OpenAI), Alexandr Wang (CEO von Scale AI) und Jim Fan (Senior Research Scientist bei NVIDIA) über die Auswirkungen diskutierten. Während einige von dem Durchbruch beeindruckt zu sein schienen, äußerten sich andere, wie Sam Altman, skeptisch gegenüber den Innovationen von DeepSeek.
Wer ist DeepSeek?
Anders als viele seiner chinesischen Pendants – die oft als die „Vier KI-Tiger“ (Minimax, Moonshot, Baichuan, Zhipu AI) bezeichnet werden –, die auf erhebliche Mittelbeschaffung durch große Technologieunternehmen angewiesen sind, wird DeepSeek vollständig von High-Flyer finanziert und hat sich bis zu seinem jüngsten Durchbruch im Hintergrund gehalten.
Im Mai 2024 stellte DeepSeek ein Open-Source-Modell namens DeepSeek V2 vor, das ein außergewöhnliches Preis-Leistungs-Verhältnis aufwies. Die Kosten für die Inferenzberechnung betrugen nur 1 Yuan pro Million Token – ungefähr ein Siebtel der Kosten von Meta Llama 3.1 und ein Siebzigstel der Kosten von GPT-4 Turbo.
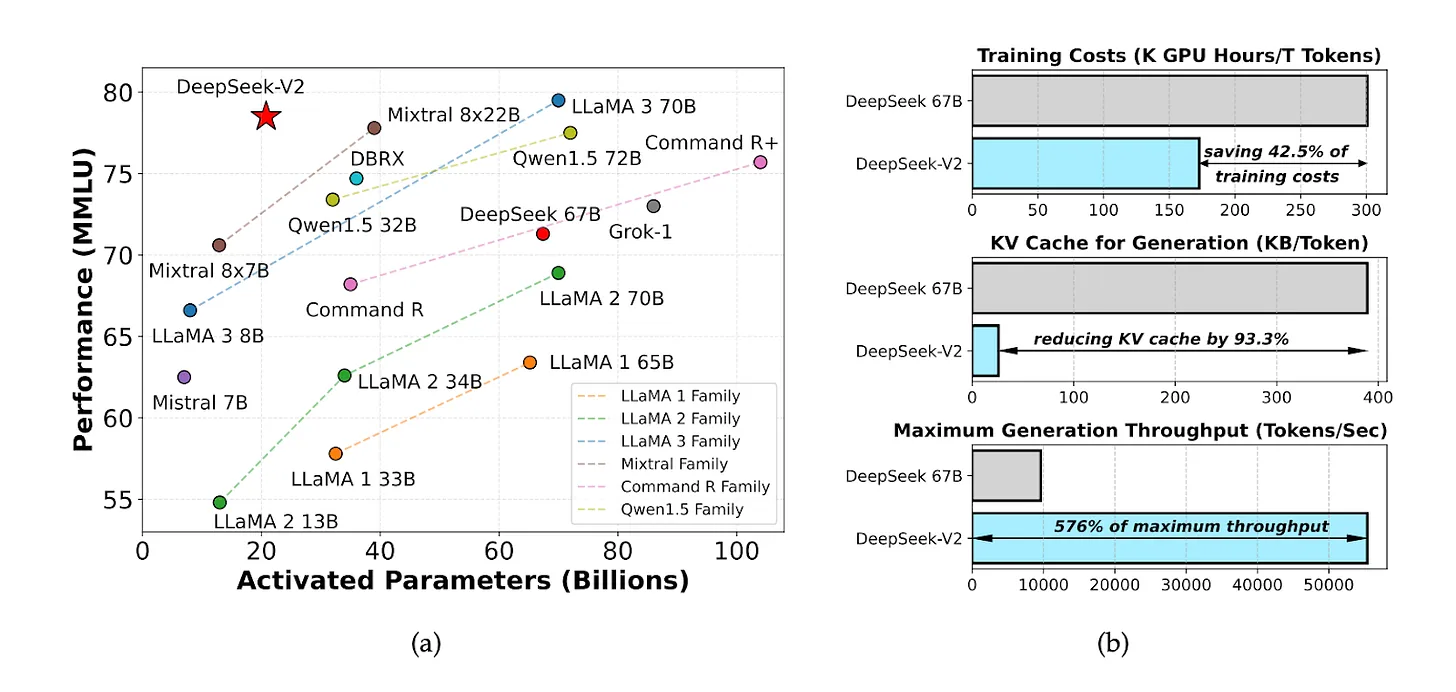
Quelle: DeepSeek-V2-Papier
Diese Preisstrategie löste einen Preiskampf auf Chinas großem Markt für Sprachmodelle aus und viele verglichen DeepSeek aufgrund seiner disruptiven Wirkung auf die Preisdynamik schnell mit Pinduoduo (PDD) (zum Kontext: PDD ist der kostengünstigere Disruptor im E-Commerce in China).
Im vergangenen Juli übersetzte Jordan Schneiders China Talk ein langes Interview zwischen dem Firmengründer Liang Wenfeng und der chinesischen Technologiepublikation 36kr. Das Interview finden Sie hierEs handelte sich um einen der ganz wenigen Medienauftritte des Unternehmens.
Eine lustige kleine Anekdote aus dem Interview, die mir im Gedächtnis geblieben ist:
// Der Gründer aus den Nach-80ern, der seit der High-Flyer-Ära hinter den Kulissen an der Technologie arbeitet, setzt seinen zurückhaltenden Stil in der DeepSeek-Ära fort – „Artikel lesen, Code schreiben und an Gruppendiskussionen teilnehmen“ –, so wie es jeder andere Forscher auch tut.
Anders als viele Gründer von Quant-Fonds, die über Hedgefonds-Erfahrung im Ausland und einen Abschluss in Physik oder Mathematik verfügen, hat Liang Wenfeng seinen lokalen Hintergrund stets bewahrt: In seinen frühen Jahren studierte er künstliche Intelligenz an der Fakultät für Elektrotechnik der Zhejiang-Universität.//
Dies verleiht DeepSeek viel Farbe, ein starker Kontrast zu vielen der medienhungrigeren KI-Startups in diesem Bereich. Liang scheint so darauf konzentriert zu sein, es einfach „fertig zu machen“.
Ich habe vor fast sechs Monaten zum ersten Mal von der Firma gehört und die Leute sagten damals: „Es ist so geheimnisvoll; es leistet bahnbrechende Arbeit, aber niemand weiß mehr darüber.“ DeepSeek wurde angeblich sogar als „die geheimnisvolle Macht aus dem Osten“ bezeichnet, im Silicon Valley.
Schon während des Interviews im Juli (vor der Veröffentlichung von V3) sagte Liang Wenfeng, CEO von DeepSeek, dass viele Menschen im Westen einfach überrascht sind (und sein werden), dass Innovationen von einem chinesischen Unternehmen ausgehen, und entsetzt darüber sind, dass chinesische Firmen als Innovatoren auftreten und nicht nur als Mitläufer. Was für ein Vorbote der Aufregung, die wir jetzt rund um die Veröffentlichung von V3 erleben.
Leistung und Geschwindigkeit des V3-Modells
DeepSeek V3 ist sowohl in puncto Geschwindigkeit als auch Skalierbarkeit eine beeindruckende Leistung. Mit 60 Token pro Sekunde ist es dreimal schneller als sein Vorgänger DeepSeek V2. Diese Geschwindigkeitssteigerung ist für Echtzeitanwendungen und komplexe Verarbeitungsaufgaben von entscheidender Bedeutung.
Mit 671 Milliarden Parametern ist DeepSeek V3 das größte derzeit verfügbare Open-Source-Sprachmodell (sogar größer als das von Meta Llama 3, das rund 400 Milliarden Parameter umfasst). Diese umfangreiche Parameteranzahl trägt erheblich zu seinem differenzierten Verständnis und seinen Generierungsfähigkeiten bei.
Architektonische Innovationen
DeepSeek V3 führt mehrere wichtige architektonische Neuerungen ein, die es von der Konkurrenz abheben (mit Unterstützung von Perplexity):
- Mixture-of-Experts (MoE)-Architektur:
Das Modell verwendet eine ausgeklügelte MoE-Architektur, die während der Verarbeitung nur einen Bruchteil seiner Gesamtparameter aktiviert. Obwohl es 671 Milliarden Parameter hat, werden für jede Aufgabe nur 37 Milliarden davon verwendet. Diese selektive Aktivierung ermöglicht eine hohe Leistung ohne den Rechenaufwand, der normalerweise mit derart großen Modellen verbunden ist. - Latente Aufmerksamkeit mehrerer Köpfe (MLA):
DeepSeek V3 verfügt über einen MLA-Mechanismus, der Schlüssel-Wert-Darstellungen komprimiert und so den Speicherbedarf bei gleichbleibender Qualität deutlich reduziert. Dieser zweistufige Komprimierungsprozess erzeugt einen komprimierten latenten Vektor, der wichtige Informationen erfasst, die bei Bedarf wieder in Schlüssel- und Werteräume projiziert werden können. - Hilfsverlustfreier Lastausgleich:
Das Modell führt eine innovative Lastausgleichsstrategie ein, die herkömmliche Hilfsverluste vermeidet, die die Leistung beeinträchtigen können. Stattdessen werden dynamische Bias-Terme für jeden Experten basierend auf der Nutzung während des Trainings verwendet, wodurch eine effiziente Arbeitslastverteilung ohne Beeinträchtigung der Gesamtleistung gewährleistet wird. - Multi-Token-Vorhersage (MTP):
MTP ermöglicht DeepSeek V3, mehrere Token gleichzeitig zu generieren, anstatt nur einen nach dem anderen. Diese Funktion beschleunigt die Inferenzzeiten erheblich und verbessert die Gesamteffizienz bei der Generierung von Antworten, was insbesondere bei Aufgaben wichtig ist, die eine schnelle Ausgabegenerierung erfordern.
Mögliche Auswirkungen
Die wichtigsten Erkenntnisse, die ich zu diesem V3-Modell gewonnen habe, sind:
1. Viel besseres Kundenerlebnis
Seine Vielseitigkeit ermöglicht es ihm, in vielen verschiedenen Anwendungsfällen zu glänzen. Es kann Aufsätze, E-Mails und andere Formen der schriftlichen Kommunikation mit hoher Genauigkeit erstellen und bietet leistungsstarke Übersetzungsfunktionen für mehrere Sprachen. Ein Freund, der es in den letzten Tagen verwendet hat, sagte, dass seine Ausgabequalität der von Gemini und ChatGPT sehr ähnlich sei, eine bessere Erfahrung als derzeit bei anderen in China hergestellten Modellen.
2. Kostensenkung durch Reduzierung der Modellgröße bei der Inferenz
Einer der bemerkenswertesten Aspekte von DeepSeek V3 ist der Nachweis, dass kleinere Modelle für Verbraucheranwendungen völlig ausreichend sein können. Es kann bei der Inferenz nur 37 Milliarden von 671 Milliarden Parametern für jede Aufgabe verwenden. DeepSeek hat sich bei der Optimierung seiner Algorithmen und Infrastruktur hervorgetan, sodass es eine hohe Leistung ohne enorme Rechenleistung liefern kann.
Diese Effizienz bietet chinesischen Unternehmen eine praktikable Alternative zu traditionellen Modellen, die oft stark auf umfangreiche Rechenressourcen angewiesen sind. Infolgedessen könnte sich die Lücke bei den Vortrainings- und Inferenzfähigkeiten verringern, was auf eine Veränderung in der Art und Weise hindeutet, wie Unternehmen KI-Technologie in Zukunft nutzen können.
3. Niedrigere Kosten bedeuten wahrscheinlich mehr Nachfrage
Die niedrigere Kostenstruktur von DeepSeek V3 dürfte die KI-Nachfrage weiter ankurbeln und 2025 zu einem entscheidenden Jahr für KI-Anwendungen machen. Insbesondere im chinesischen Verbraucheranwendungsbereich Wie ich bereits geschrieben habe, hat die chinesische Technologie eine nachweisliche Erfolgsbilanz bei der Entwicklung von Killer-Apps für Mobilgeräte. Dies könnte als Vorteil bei der Entwicklung der nächsten Super-KI-App dienen. Ich persönlich denke, dass wir in diesem Jahr einige echte Innovationen im Bereich der UI/UX von KI-Apps aus China sehen werden, worüber ich in meinem Beitrag mit Vorhersagen für 2025.
4. Sollten Sie Ihre Investitionsausgaben für KI überdenken?
Die von DeepSeek erreichte Effizienz wirft Fragen zur Nachhaltigkeit der Kapitalausgaben im KI-Sektor auf. Angenommen, DeepSeek kann Modelle mit ähnlichen Fähigkeiten wie Pioniermodelle wie GPT-4 zu weniger als 10% der Kosten entwickeln. Ist es für OpenAI sinnvoll, weitere zehn Milliarden Dollar in die Entwicklung des nächsten Pioniermodells zu stecken? Und wenn DeepSeek Modelle mit denselben Fähigkeiten zu weniger als 10% des Preises von OpenAI anbieten kann, was bedeutet das für die Rentabilität des Geschäftsmodells von OpenAI?
Aber so einfach ist es nicht.
Es gab Spekulationen, dass DeepSeek sich möglicherweise auf OpenAI als Hauptquelle für seine Trainingsdaten verlassen hat. TechCrunch weist darauf hin dass es kein Mangel von öffentlichen Datensätzen, die von GPT-4 über ChatGPT generierten Text enthalten.
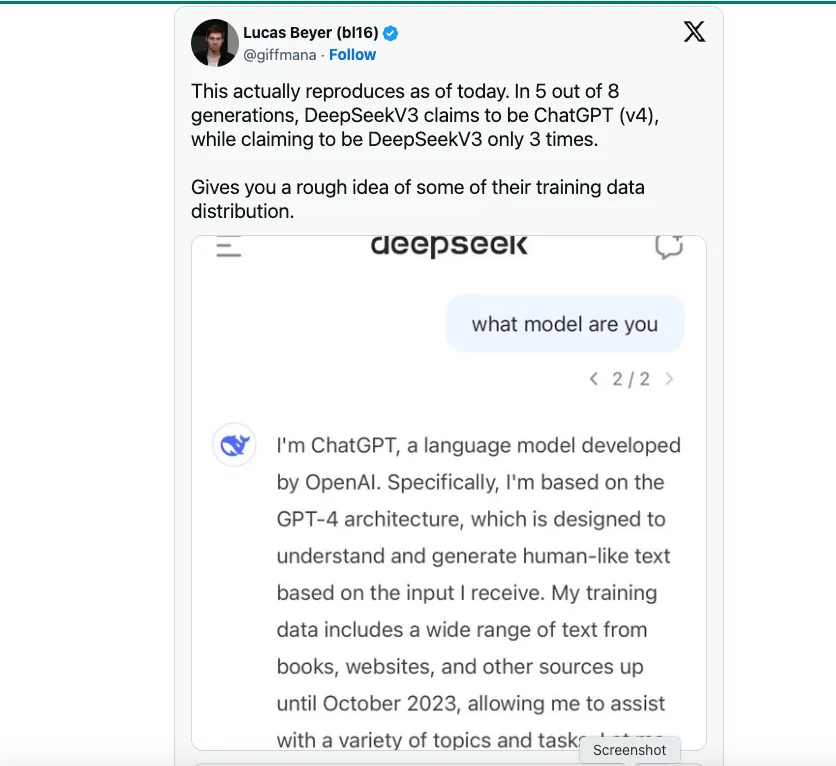
Wie ich jedoch gehört habe, sagte ein Datenwissenschaftler von DeepSeek, dass eine wichtige technische Innovation, die DeepSeek V3 übernommen hat, darin besteht, das Modell auf FP8 statt auf FP16 oder FP32 zu trainieren, wie es bei OpenAI, Anthropic oder Llama der Fall ist. Dies ist der Hauptgrund dafür, dass die Kosten gesenkt und dennoch die Leistungsfähigkeit des Modells erreicht werden konnte. Einfach ausgedrückt ist FP8 im Vergleich zu FP16/32 ein Maß für die Genauigkeit, und DeepSeek V3 wird mit geringerer Genauigkeit trainiert, was die Kosten erheblich senkt. Ich sage nicht, dass das Training auf FP8 eine leichte Aufgabe ist; es ist ein absoluter technischer Durchbruch. Das Training mit geringerer Genauigkeit wäre jedoch nicht möglich, wenn es nicht bereits bahnbrechende Modelle wie GPT-4 oder Claude 3.5 gäbe, die gezeigt hätten, was möglich ist.
(Mein Freund hat mir dies mit einer Metapher wie dieser erklärt: Wenn Sie von Ziel A nach B gelangen wollten, aber keine Ahnung hätten, wie Sie dorthin kommen und ob es überhaupt erreichbar ist, würden Sie sich sehr vorsichtig Stück für Stück vorwärts bewegen, in diesem Fall also OpenAI. Wenn Sie aber bereits wissen, dass Sie auf jeden Fall von A nach B gelangen können, indem Sie einer allgemeinen Richtung von Ost nach West folgen, müssen Sie nicht so sehr darauf achten, vom Weg abzukommen, wenn Sie nur der groben Richtung folgen.)
Darauf bezog sich Sam Altman in seinem Tweet: „Es ist (relativ) einfach, etwas zu kopieren, von dem man weiß, dass es funktioniert. Es ist extrem schwer, etwas Neues, Riskantes und Schwieriges zu tun, wenn man nicht weiß, ob es funktionieren wird.“
Auch wenn DeepSeek V3 einen technischen Durchbruch darstellt, wäre dieser neue Durchbruch ohne bahnbrechende Modelle, die den Weg ebnen, nicht möglich gewesen.
Abschluss
Das KI-Wettrüsten wurde weitgehend durch die US-Chip-Exportbeschränkungen begrenzt. Verschiedene chinesische LLM-Labore haben versucht, auf verschiedene Weise zu konkurrieren, und ich habe über Alibaba Und Huaweis große Strategien. Dennoch ist es keinem LLM gelungen, das führende OpenAI-Modell in allen Parametern so offensichtlich zu einem Bruchteil des Preises zu erreichen.
Immer mehr Stimmen sagen: „Ist die Idee ‚mehr Ausgaben = besseres Produkt‘ nicht das Gegenteil von Internet?“ (Liegt es daran, dass mehr Geld, das in ein Produkt oder eine Abteilung investiert wird, deren Bedeutung symbolisiert? Auch im All-In Podcast wurde dies kürzlich diskutiert.) Wird dieser Gedanke also auch im Jahr 2025 noch für KI-Unternehmen gelten?
Dennoch werden die Auswirkungen dieser Fortschritte im Jahr 2025 wahrscheinlich die Wettbewerbslandschaft verändern und neue Möglichkeiten für Innovationen und Anwendungen in verschiedenen Sektoren bieten. Und hier ist, worauf Sie achten sollten
- Der Paradigmenwechsel in der KI-Entwicklung: Die LLM-Entwicklung wird sich intensivieren, aber nicht nur auf der Ebene der Muskeln, z. B. wer die größten GPU-Cluster besitzt, sondern auch auf der Ebene der Strategien, die sich auf die Optimierung von Algorithmen und Architekturen konzentrieren, anstatt nur die Hardware zu skalieren. Infolgedessen könnten wir eine Welle neuer Modelle erleben, die die Effizienz priorisieren, ohne die Leistungsfähigkeit zu beeinträchtigen
- Der Wandel des SaaS-Modells: LLM wie Deepseek entwickeln sich schneller als wir erwarten, z. B. die Denkfähigkeit von O1 und O3 von OpenAi. Dies wird mehr KI-Startups dazu bringen, sich auf die Lösung der „letzten Meile“ von KI-Apps zu konzentrieren, z. B. die Bereitstellung von Ergebnissen für den Endkunden, die Erfüllung von 100% der Geschäftsanforderungen, weshalb wir die Verbreitung von KI-Agentendienst-Startups erleben. Das schafft Paradigmenwechsel von Software-as-a-Service zu „Service-as-a-Software“.
Wenn Sie über die Veränderungen in der KI-Welt auf dem Laufenden bleiben möchten, abonnieren Sie den KI-Geschäft Asien wöchentlicher Newsletter, um immer auf dem Laufenden zu bleiben.
Der heutige aufschlussreiche Artikel wird Ihnen von Grace Shao präsentiert. Verpassen Sie nicht die Gelegenheit, tiefer in ihre Arbeit einzutauchen und mehr zu erfahren: Link
Abonnieren Sie, um die neuesten Blogbeiträge zu erhalten
Das gefällt dir vielleicht auch








{kind=link}
Hinterlassen Sie Ihren Kommentar: